Schon bald nach unserer
Wahl am 22. Juni haben wir im Präsidium von Wikimedia
Deutschland festgestellt: In seiner aktuellen Zusammensetzung fehlt
dem Präsidium eine starke Stimme aus der ehrenamtlichen
Wikipedia-Community. Deshalb haben wir uns dazu entschlossen, von
der Möglichkeit der Kooptation Gebrauch zu machen. Unter der
Kooptation versteht man die Ernennung von bis zu zwei weiteren
Präsidiumsmitgliedern, um benötigte Kompetenzen und Erfahrungen zu
verstärken und die Diversität des Gremiums zu fördern.
Eine der wesentlichen Aufgaben unseres Vereins ist die Förderung
der vielen Ehrenamtlichen, die jeden Tag aufs Neue Inhalte in den
verschiedenen Wikimedia-Projekten überarbeiten oder neu erstellen.
Dass ihre Perspektive auch im Präsidium von Wikimedia Deutschland
vertreten ist, finden wir deshalb besonders wichtig. Natürlich
bringen die gewählten Präsidiumsmitglieder bereits großartige
Expertise mit, etwa durch langjährige Mitarbeit in Wikipedia,
Wikimedia Commons und Wikidata. Eine Person, die selbst bestens in
der deutschsprachigen Community vernetzt ist, Rollen und Funktionen
übernimmt – das fehlt uns bislang jedoch.
Bestens vernetzt in der
ehrenamtlichen Community
Die Wahl einer geeigneten Person, die dieses Anforderungsprofil
erfüllt, ist uns nicht schwer gefallen: Raimond Spekking ist seit
über 20 Jahren ein aktives und sehr geschätztes Mitglied der
Community. Neben seiner inhaltlichen Mitarbeit in der Wikipedia ist
er unter anderem auch im ehrenamtlichen Support-Team der Wikipedia
tätig und entwickelt die MediaWiki-Software als Developer
weiter.
Sein Interesse für Fotografie schlägt sich in den unzähligen
Bildern nieder, die er in der Wikipedia und bei Wikimedia Commons
beigesteuert hat, zuletzt etwa im Zuge einer
Kooperation mit dem Deutschen Technikmuseum. Bei Wikimedia
Commons engagiert sich Raimond auch als Administrator. Darüber
hinaus trägt Raimond ehrenamtlich zu Wikidata bei und unterstützt
u. a. Kulturinstitutionen dabei, Bestände zu digitalisieren und
unter freie Lizenzen zu stellen.
Erfahrung in der
Präsidiumsarbeit
Raimond war bereits im letzten Präsidium tätig und hat in dieser
Rolle immer wieder die so wichtige Perspektive aktiver Beitragender
eingebracht. Bei der Mitgliederversammlung am 22. Juni kandidierte
er als Beisitzer und erhielt 310 Stimmen von den Mitgliedern, nur
vier weniger als der fünfte gewählte Beisitzer. 73 Prozent der
Wählenden stimmten für ihn – für uns ein starkes Signal, dass er
den Rückhalt aus der Mitgliedschaft hat.
Lieber Raimond, im Namen des ganzen Präsidiums heiße ich dich
herzlich willkommen im 9. Präsidium und freue mich sehr auf die
erneute Zusammenarbeit mit dir!
Alice Wiegand
Vorsitzende des Präsidiums
Wikimedia Deutschland e. V.
Aktuell hat ein Fotograf den gemeinnützigen Softwareentwickler
LAION e. V. verklagt. Er wirft dem Verein die unrechtmäßige Nutzung
eines seiner Bilder für KI-Training vor. Wikimedia Deutschland
verfolgt den Fall mit großem Interesse, weil damit erstmals eine
gerichtliche Einschätzung zur Rechtslage der Datennutzung für
KI-Training erfolgt und das Urteil wegweisend für die Arbeit der
Open-Source-Communitys im KI-Bereich sein wird.
Für Wikimedia Deutschland verfolgt unsere Justiziarin und
Rechtsanwältin Dr. Saskia Ostendorff den Rechtsstreit am
Landgericht Hamburg.
“Was hier am Ende des Rechtsstreits entschieden wird, wird auch
Auswirkungen auf die Arbeit von Wikimedia haben, gerade was unsere
Arbeit in der Softwareabteilung mit Open-Source-Communitys
betrifft.”
Das ist die
Ausgangssituation
Der verklagte Verein LAION
ist eine gemeinnützige Organisation, die Datensätze, Werkzeuge und
Modelle zur Verfügung stellt, um die Forschung im Bereich des
maschinellen Lernens zu fördern. Der Verein hat den frei
verfügbaren Datensatz LAION
5B erstellt, in welchem auch das Bild des klagenden Fotografen
enthalten war. Das Bild stammt ursprünglich von der Website
Bigstock.com, wo ein Nutzungsvorbehalt aufgeführt wurde. Mit dieser
Klausel sollte ausgeschlossen werden, dass Bilder der Plattform u.
a. für KI-Trainings verwendet werden. Jedoch steht jetzt vor
Gericht zur Debatte, ob die Form des Nutzungsvorbehalts den
aktuellen Anforderungen genügt.
Im Kern dreht sich der Rechtsstreit nun also darum, ob LAION eine Urheberrechtsverletzung
begangen hat und ob der Nutzungsvorbehalt von Bigstock in seiner Form gültig war.
Der klagende Fotograf argumentiert, dass seine Verwertungsrechte
verletzt wurden, da LAION das
Bild für den Trainingsdatensatz trotz des Nutzungsvorbehalts von
Bigstock verwendet hat. LAION beruft sich hingegen
auf die Text- und Data-Mining-Schranke des § 44b UrhG. Danach sind
Vervielfältigungen von rechtmäßig zugänglichen Werken, wie das Bild
des Fotografen, für Text und Data-Mining zulässig. Das ist nur dann
nicht der Fall, wenn der Fotograf sich die Nutzung zum Text- und
Data-Mining in maschinenlesbarer gültiger Form vorbehalten hat.
Das ist Text oder Data
Mining
Text- und Data-Mining (TDM) sind Forschungsmethoden, mit denen
große Mengen Daten oder Text zusammengefasst und analysiert werden
können. Beim Data-Mining liegt der Fokus auf Daten, beim
Text-Mining auf Volltexten aus wissenschaftlichen Zeitschriften,
Romanen oder ähnlichem. Bevor die Datenmenge oder Texte analysiert
werden können, werden sie systematisch und maschinenlesbar
aufbereitet. Anschließend können sie mit computergestützten
Analysen automatisiert auf Muster oder Zusammenhänge hin untersucht
werden. Ein bekanntes Beispiel für Text-Mining ist das Project
Robots Reading Vogue der Yale University, bei
dem der Korpus der Vogue Ausgaben nach verschiedenen Fragen auf
Muster hin analysiert wird.
Rechtliche Auseinandersetzung
zum Text- und Data-Mining
Das Gericht fokussierte sich auf die Anwendung des § 44b UrhG,
den es grundsätzlich für das Auslesen und Überprüfen der Daten als
anwendbar ansieht. Die Frage, ob § 44b UrhG auch für das Training
von KI-Modellen gilt, ließ das Gericht offen und verwies darauf,
dass dies möglicherweise eine Vorlagefrage für den Europäischen
Gerichtshof sei.
Das Gericht betonte, dass die gesamte Kreativbranche vor der
Herausforderung steht, dass KI die Erstellung von Werken übernehmen
könne und der Fall auch vor diesem Hintergrund bewertet werden
müsse.
Weiterhin ging es vor allem darum, wie ein Nutzungsvorbehalt
aussehen und in welcher Form er maschinenlesbar sein muss. Der
Nutzungsvorbehalt wurde von der Plattform Bigstock vorgebracht,
nicht vom Fotografen, der geklagt hatte. Das Gericht stellte klar,
dass es nicht entscheidend ist, von wem der Nutzungsvorbehalt kommt
– die Erklärung der Plattform macht sie auch für den Fotografen
wirksam. Diese Einschätzung wurde zunächst nicht weiter
begründet.
Es wurde lange diskutiert, wie ein maschinenlesbarer
Nutzungsvorbehalt gestaltet sein sollte. Reicht schon ein
schriftlicher, für Menschen lesbarer Nutzungsvorbehalt oder ist ein
spezielles technisches Format nötig, das von Maschinen gelesen
werden kann?
Entscheidung Ende September
erwartet
Die Entscheidung des Falls, ob LAION das Bild des Fotografen für
den Trainingsdatensatz nutzen durfte, trifft sich nun also an dem
Merkmal der Maschinenlesbarkeit des Nutzungsvorbehalts zum
Ausschluss des Text- und Data-Mining.
Beim Begriff “Maschinenlesbarkeit” in § 44b UrhG erklärte das
Gericht, dass es zwei Auffassungen des Begriffs gibt: eine weite
und eine enge. Nach der weiten Auffassung, ist ein
Nutzungsvorbehalt maschinenlesbar, wenn er irgendwie digital
erfassbar ist, während die enge Auffassung ein strukturiertes
Dateiformat fordert, das maschinell auslesbar ist. Die KI-Verordnung erfordert einen
modernen Standard, ohne diesen näher zu konkretisieren. LAION
argumentiert, dass z. B. das Dateiformat robot.txt ein solcher
Standard sei, während der Kläger dies als wenig praktikabel für
Rechteinhaber kritisierte.
Das Gericht hat am Ende der Verhandlung noch keine endgültige
Entscheidung getroffen, diese wird für den 27. September 2024
erwartet.
Die Bedeutung des Falls für die
Open-Source-Community und für freies Wissen
Der erste Rechtsstreit zur Nutzung von KI-Modellen in Hamburg
könnte bedeutende Auswirkungen auf die Open-Source-Community haben.
Dieser Fall könnte nicht nur rechtliche Klarheit im Hinblick auf
die Anwendung der Text- und Data-Mining-Schranke in § 44b UrhG
bringen. Er könnte auch die Art und Weise beeinflussen, wie frei
zugängliche Werke in Open-Source-Datasets genutzt werden dürfen.
Eine Entscheidung zugunsten des Klägers könnte die Nutzung solcher
Werke einschränken. Andererseits wird der Fall die gegenwärtig
unklaren Rahmenbedingungen für einen maschinenlesbaren
Nutzungsvorbehalt klarstellen.
Es wurde ebenfalls bereits deutlich, dass es nicht bei der
Entscheidung des Landgerichts bleiben wird. Das Gericht
signalisierte, dass es die Auslegung des Gesetzes als eine
Vorlagefrage für den Europäischen Gerichtshof sieht. Demnach ist
damit zu rechnen, dass sich der Rechtsstreit über mehrere Jahre
ziehen wird und die rechtlichen Unklarheiten bis zum Abschluss des
Verfahrens bestehen bleiben.
Dennoch wird die Entscheidung im September erste offene Fragen in
Bezug auf die rechtliche Bewertung für die Trainingsdatensätze von
KI-Modellen klären.
International gibt es den Fotowettbewerb Wiki Loves Folklore (WLF)
bereits seit fünf Jahren. Er hat sich neben Wiki Loves Monuments (WLM) und Wiki Loves Earth (WLE) als weiterer
Wettbewerb für Fotos unter freier Lizenz etabliert, zu dem die
Freiwilligen der Wikimedia-Projekte weltweit beitragen. Knapp
80.000 Mediendateien aus 168 Ländern sind im Zuge von WLF schon
zusammengekommen. Sie stehen auf Wikimedia Commons unter freier Lizenz zur
Verfügung und werden vor allem in der Wikipedia genutzt.
In diesem Jahr hat sich erstmals auch die deutsche
Wiki-Community an WLF beteiligt. Über 2600 Bilder und Videos wurden
zwischen Anfang Februar und Ende März eingereicht. Jetzt hat eine
Jury aus der Community in Magdeburg ihre Auswahl getroffen und die
50 besten Fotos prämiert.
Geistervertreibung und
Kirmesvergnügen
Den 1. Platz hat Wikipedianer Mölchlein mit
seinem Foto Erstellung einer Maske für den Kirchseeoner
Perchtenlauf in Kirchseeon, Bayern belegt. Die Deutsche
UNESCO-Kommission hat mittlerweile beschlossen, den Kirchseeoner
Perchtenlauf in das deutsche Register des Immateriellen Kulturerbes
aufzunehmen. Die Jury war besonders beeindruckt, „wie detailliert
die traditionelle Handwerkstechnik und die Leidenschaft des
Handwerkers im Bild eingefangen wurden.“
1. Platz: Der Schnitzer Herbert Schafbauer
erstellt eine Maske mit Leitidee vom Nonnenfalter, der im Wappen
Kirchseeon geführt wird. Der Kirchseeoner Perchtenlauf ist ein
winterlicher Umzugsbrauch, bei dem eine Gruppe aus unterschiedlich
maskierten Gestalten durch die Gemeinde Kirchseeon zieht und Tänze,
Gesänge und Sprüche aufführt. Die Kirchseeoner Perchten stellen
Glücksbringer dar, die das neue Jahr und die neue
Vegetationsperiode einläuten. Foto: Jan Czeczotka, Kirchseeoner
Perchtenlauf 2023-2024 – der Schnitzer Herbert Schafbauer erstellt
eine Maske mit Leitidee vom Nonnenfalter, der im Wappen Kirchseeon
geführt wird, CC BY-SA 4.0
Der 2. Platz geht an Superbass für das Bild
Winteraustreibung „Schewe Sunnesch“ in Gees (Gerolstein),
Rheinland-Pfalz. Bei diesem Brauch in der Eifel wird ein mit
Stroh gefülltes Rad brennend den Berg hinab gerollt. Der Glaube
besagt: Je ruhiger das Rad läuft, desto besser wird das Jahr.
2. Platz: Bei der Winteraustreibung
“Schewe Sunnesch” in Gees wird ein mit Stroh gefülltes Rad brennend
den Berg hinabgerollt. Vor dem brennenden Rad wird eine Bahn aus
Stroh ebenfalls in Brand gesetzt. Foto: Superbass,
2024-02-17-Schewe Sunnesch-2331, CC BY-SA 4.0
Platz 3 belegt Würmchen mit Klaubauf
Nasenzuzler mit Fackel beim Kirchseeoner Perchtenlauf in Moos im
Landkreis Ebersberg, Bayern. Das Foto zeigt den winterlichen
Umzugsbrauch, für den die Maske auf dem Bild von Mölchlein
gefertigt wurde. Die Kirchseeoner Perchten wollen mit ihren Tänzen
und Sprüchen, die sie vor den Häusern aufführen, die guten
Erdgeister erwecken und die bösen abschrecken.
3. Platz: Der Kirchseeoner Perchtenlauf
ist ein winterlicher Umzugsbrauch. Dabei erinnern die Kirchseeoner
Perchten, dass die Menschen von den Launen der Natur schon immer
abhängig waren und sind. Foto: Ursula Jaeger, Kirchseeoner
Perchtenlauf 2023-2024 in Moos – Maske vom Zuzler mit Fackel, CC
BY-SA 4.0
Über den 4. Platz darf sich Rainer Halama mit
Send in Münster, Nordrhein-Westfalen, 2019 freuen. Aus der
Bewertung der Jury: „Durch den lebendigen Bildaufbau mit den
umgebenden glitzernden Buden der Schausteller und der Geisterbahn
fühlt man sich wie ein Kind, das zum ersten Mal auf einer Kirmes
ist und ständig etwas neues entdeckt.” Rainer Halama wurde außerdem
mit einem Sonderpreis für sein VideoNarrentag 2024 des
Viererbund in Oberndorf am Neckar im Landkreis Rottweil,
Baden-Württemberg ausgezeichnet.
4. Platz: Der Send ist das dreimal
jährlich im westfälischen Münster stattfindende Volksfest, das pro
Jahr mehr als eine Million Besucher zählt. Foto: Rainer Halama,
Münster-Send-2019-0167, CC BY-SA 4.0
Auf Platz 5 hat die Jury Blende-sd mit
Brucker Perchte in Fürstenfeldbruck, Bayern, 2021 gewählt.
„Wie frisch vom Plattencover einer Metalband” komme die Perchte
daher, besonders gefiel den Juror*innen „die geheimnisvolle,
mystische Stimmung seines Bildes.”
5. Platz: Das alljährlich in den Voralpen
stattfindende Brauchtum, das die bösen Geister vertreiben und Glück
für das neue Jahr bringen soll. Foto: Blende-sd, Brucker Perchte
II, CC BY-SA 4.0
Lust, bei den Fotowettbewerben mitzumachen?
Wer nun Lust bekommen hat, selbst die Kamera in die Hand zu
nehmen, kann sich schon mal in Vorfreude üben: Im September rufen
die Ehrenamtlichen der Wikipedia und des freien Medienarchivs
Wikimedia Commons zur neuen Runde von Wiki Loves
Monuments auf. Alle Details dazu werden wir auch wir hier im
Blog und auf unseren Social Media-Kanälen veröffentlichen.
In Deutschland engagieren sich tausende Menschen ehrenamtlich
für Demokratie und politische Bildung, betreiben gemeinnützigen
Journalismus oder entwickeln und pflegen Freie bzw. Open Source
Software. Und doch sind diese Zwecke bislang nicht oder nicht
explizit Teil des Katalogs gemeinnütziger und damit
steuerbegünstigter Zwecke. Oder die Organisationen müssen, wie im
Fall des Engagements für die Demokratie und gegen
Rechtsextremismus, darauf hoffen, dass Finanzämter unklare
Formulierungen in der Abgabenordnung zu ihren Gunsten auslegen. Das
schafft keine Rechtssicherheit.
Die Abgabenordnung, oder genauer gesagt der Paragraph 52,
regelt, welche Tätigkeiten von den Finanzämtern als gemeinnützig
eingestuft werden und damit steuerbegünstigt sind. Dazu gehören
etwa die Förderung des Tierschutzes, des Sports, der Kunst und
Kultur oder Wissenschaft und Forschung. Auch die Förderung des
demokratischen Staatswesens ist unter bestimmten Bedingungen
gemeinnützig. Insgesamt 26 Zwecke sind gelistet. Aber die
Abgabenordnung ist lückenhaft und veraltet. Das zeigen immer wieder
Fälle, in denen Vereinen, die dem Gemeinwohl dienen, die
Gemeinnützigkeit entzogen wird.
In einem eigenen Positionspapier und in einem
offenen Brief mit der Allianz Rechtssicherheit für politische
Willensbildung machen wir konkrete Vorschläge für notwendige
Ergänzungen und Änderungen in der Abgabenordnung.
Wer fällt durch die Lücken in der Abgabenordnung und was muss
sich ändern?
Engagement für ein besseres
Internet unterstützen
Mastodon ist ein dezentrales,
nicht-kommerzielles und von Communitys selbst verwaltetes
Kommunikationsnetzwerk. Darüber, welche Inhalte Nutzende sehen
entscheidet kein Algorithmus. Besonders polarisierende oder
schockierende Inhalte werden nicht bevorzugt, um Nutzende im
Netzwerk zu halten. Mastodon ist einer der wenigen Gegenspieler zu
den toxischen Social Media Plattformen der Tech-Giganten. Mastodon
wurde als Freie Software entwickelt und die Pflege sowie der
Betrieb der Server werden fast ausschließlich spendenfinanziert.
Das Mastodon auf Freier Software basiert, bedeutet zudem: Sie kann
nicht von Unternehmen privatisiert werden. Jede und jeder kann
Freie Software für eine eigene Anwendung nutzt und diese auch
weiterentwickelt – muss die Resultate oder Verbesserungen dann auch
frei zur Verfügung stellen. Daher sollten Freie Software-Projekte
in der Abgabenordnung explizit als gemeinnützig gelistet werden.
Die Bundesregierung behauptet, die Anerkennung als gemeinnützig
werde durch die Zwecke der Förderung der Wissenschaft oder der
Bildung bereits abgedeckt. Eine explizite Aufnahme in die
Abgabenordnung sei daher nicht notwendig. Dass das nicht stimmt,
zeigt die Aberkennung der Gemeinnützigkeit von
Mastodon 2024.
Wir fordern daher in unserem Positionspapier, dass auch die
Entwicklung gemeinwohlorientierter und freier Software, Plattformen
oder Apps als gemeinnützig gilt. Ergänzend könnte auch der
Unterhalt und Betrieb dieser Netzwerke in die Auflistung der
Zweckbetriebe in § 68 AO aufgenommen werden. Der Begriff
Zweckbetrieb meint die wirtschaftlichen Unternehmungen eines
gemeinnützigen Vereins, mit denen er seinen nicht-wirtschaftlichen
Vereinszwecke fördert. Dazu gehören beispielsweise Altenpflege,
Kinder- und Jugendarbeit oder Inklusionsarbeit.
Erst eine explizite Aufnahme von Open Source Entwicklung und
Pflege als gemeinnütziger Zweck in die Abgabenordnung schafft die
notwendige Rechtssicherheit. Politikschaffende können nicht
einerseits – und völlig zurecht – die Tech-Giganten kritisieren und
dann keine Anstrengungen unternehmen, um die Menschen zu fördern,
die sich für ein besseres Internet engagieren.
Grafik: Mastodon gGmbH, Mastodon Welcome,
CC BY-SA 4.0
Wer sich auf der ursprünglichen,
Mastodon-eigenen Instanz ein Profil zulegt, wird ersteinmal
freundlich begrüßt. Auch auf Mastodon herrscht nicht immer eitel
Sonenschein, aber der Tonfall und Umgang sind nicht zu vergleichen
mit dem oft hasserfüllten und diskriminierenden Verhalten von
Nutzenden auf Plattformen wie X/Twitter. Grafik: Mastodon gGmbH,
Mastodon Welcome, CC BY-SA 4.0
Journalismus geht auch
gemeinnützig – wenn er denn anerkannt wird
2014 als Blog gegründet, betreibt Volksverpetzer seit nunmehr
zehn Jahren spendenfinanzierten Journalismus. Das Portal hat sich
darauf spezialisiert, Desinformation und Falschmeldungen
aufzudecken. Es ist einer der Vorreiter der mittlerweile
zahlreichen journalistischen Faktencheck-Angebote im Netz. Die
Inhalte des Blogs sind kostenfrei verfügbar, zahlreiche
„Mitarbeitende“ recherchieren, schreiben und redigieren
ehrenamtlich für den Blog. 2019 hatte das Finanzamt anerkannt, dass
der Blog sich mit seinem Engagement gegen Desinformationen und
allerlei Formen von gruppenbezogener Menschenfeindlichkeit für die
„internationale Gesinnung“ einsetzt. Unter Nummer 13 ist dies als
gemeinnütziger Zweck in der Abgabenordnung gelistet. 2021 wurde die
Gemeinnützigkeit bestätigt. In diesem Jahr wurde dem Volksverpetzer
dann die Gemeinnützigkeit entzogen. An den Inhalten des Blogs hatte
sich nichts geändert. Auch die Finanzierung über Spenden sowie der
kostenfreie Zugang zu den Inhalten sind weiterhin gegeben.
Die Ampel-Koalition hat die Aufnahme gemeinwohlorientierten
Journalismus in die Liste der steuerbegünstigten Zwecke im
Koalitionsvertrag vereinbart. Wir halten es für relevant, dieses
Ziel gesetzlich zu regeln und schlagen den freien und nicht mit
Bezahlhürden verbundenen Zugang zu den Inhalten als ein Kriterium
vor.
Politische Bildung muss
rechtssicher möglich sein
Das Demokratische Zentrum Ludwigsburg veranstaltet seit 1980
Lesungen, Kabarettabende und Konzerte, bietet Workshops zur
politischen Bildung an und engagiert sich gegen Rassismus,
Homophobie und andere menschenfeindliche Einstellungen. Es fördert
also gleichzeitig die Kultur und das demokratische Staatswesen –
zwei Zwecke aus der Abgabenordnung. 2019 wurde dem Zentrum die
Gemeinnützigkeit entzogen. Es hatte sich geweigert, Rechtsextreme
zu seinen politischen Bildungsveranstaltungen zuzulassen. Das
Finanzamt sah darin eine Verletzung des Prinzips der „geistigen
Offenheit“. Mehr über den dreijährigen Rechtsstreit, an dessen Ende
das Zentrum die Gemeinnützigkeit zurück erhielt, erfahren Sie hier. Das Problem: Eine
restriktive Auslegung des Prinzips der „geistigen Offenheit“ führt
dazu, dass in der Erinnerungsarbeit und der politischen Bildung die
Aufklärung über und Positionierung gegen rassistische,
antisemitische oder anderweitig demokratiefeindliche Einstellungen
zu einer Aberkennung der Gemeinnützigkeit führen kann.
In einem offenen Brief der Allianz
Rechtssicherheit für politische Willensbildung, den Wikimedia
Deutschland unterstützt, haben wir Vorschläge gemacht, wie die
Abgabenordnung zu verändern ist, damit gemeinnützige Vereine,
die:
sich für ihre Vereinszwecke auch durch Äußerungen zu
tagespolitischen Themen einsetzen,
an der politischen Willensbildung mitwirken oder
politische Bildung betreiben
dies auch tun können, ohne um den Status der Gemeinnützigkeit
fürchten zu müssen.
In Paragraph 52 Absatz 2 Satz 2 unter Nummer 24 sollte der Zweck
künftig lauten:
24. die allgemeine Förderung des demokratischen Staatswesens
einschließlich der demokratischen Teilhabe, insbesondere
der politischen Bildung (im Geltungsbereich dieses
Gesetzes;) hierzu gehören nicht Bestrebungen, die nur bestimmte
Einzelinteressen staatsbürgerlicher Art verfolgen oder (die auf den
kommunalpolitischen Bereich beschränkt sind) die umfassende
Unterstützung von einzelnen Parteien oder Wählergemeinschaften
verfolgen; — Anmerkung: Gefettete Passagen sind neu in dem
Satz, Passagen in Klammern sind alt und sollten gestrichen
werden.
Zudem sollte der § 58 der Abgabenordnung um den Passus ergänzt
werden: „Gemeinnützige Zwecke werden auch dann nach Absatz 1 Satz 1
verfolgt, wenn eine Körperschaft sie durch die Mitwirkung an der
politischen Willensbildung und der Bildung der öffentlichen Meinung
fördert.“
Was sagt der aktuelle
Entwurf?
Im Referentenentwurf zum Jahressteuergesetz II wird lediglich §
58 der Abgabenordnung erweitert. Wenn der Entwurf Gesetz würde,
hieße das, dass gelegentliche Stellungnahmen eines gemeinnützigen
Vereines zu tagespolitischen Themen diesen Verein nicht mehr von
der Gemeinnützigkeit ausschließen. Diese Ergänzung begrüßen wir,
weil sie Rechtssicherheit schafft. Sie fällt jedoch hinter
die genannten Lösungsvorschläge und Forderungen aus der
Zivilgesellschaft weit zurück. Finanzämter erhalten damit weiterhin
keine ausreichend deutlichen Definitionsrahmen für gemeinnützige
Zwecke. Auch weitere Vorhaben aus dem Koalitionsvertrag, wie die
Anerkennung von gemeinnützigem Journalismus, sind im derzeitigen
Referentenentwurf nicht realisiert worden.
Noch handelt es sich um einen Referentenentwurf. In einer
Stellungnahme, die wir dem Bundesministerium der Finanzen haben
zukommen lassen, appellieren wir an die Bundesregierung, diesen
Entwurf im Verlauf der Verbändebeteiligung im Sinne der
organisierten Zivilgesellschaft zu überarbeiten. Gemeinnützigkeit,
wem Gemeinnützigkeit gebührt!
Das Thema Wissensgerechtigkeit liegt Lee Modupeh Anansi Freeman
in mehrfacher Hinsicht am Herzen. Persönlich und politisch. „Zum
einen bin ich eine Person afrikanischer Herkunft und kenne
Generationen meiner eigenen Familie nicht – weil unser Wissen
systematisch gelöscht und zerstört wurde.“ Zum anderen, stellt
Freeman fest, „leben wir in einer Ära der Desinformation. Je mehr
Raum die verdrängten Stimmen bekommen, desto besser können wir
dagegen ankämpfen.“
Lee Modupeh Anansi Freeman zählt zu den Teilnehmenden der ersten
Ausgabe des Förderprogramms re•shape, mit dem Wikimedia Deutschland
sich für die Sichtbarkeit von marginalisiertem Wissen stark macht.
In Kooperation mit den neuen deutschen organisationen – das
postmigrantische Netzwerk e.V., einem Verbund von fast 200
Vereinen, Initiativen und Selbstorganisationen, ist im Dezember
2023 ein Call mit beachtlicher Resonanz gestartet worden: Fast 90
Projekte bewarben sich auf die erste re•shape-Runde, zehn davon
wurden gefördert. Ein unabhängiges Kuratorium aus Hajdi Barz,
Juliana Kolberg und Victoria Kure-Wu hat das vierköpfige
Programmteam von Wikimedia Deutschland bei der Konzeption des
Programms unterstützt und gemeinsam mit einer Vertretung von
Wikimedia und den neuen deutschen Organisationen e.V. die Projekte
ausgewählt.
Foto: Christopher Schwarzkopf
Ein Programm, das neues Denken
braucht
Zu den geförderten Vorhaben zählt auch das TRAP$ Academy-Projekt
von Lee Modupeh Anansi Freeman und Farah Abdullahi Abdi, das sich
der Weitergabe von Wissen innerhalb der Black Trans/GNC (Gender
Non-Conforming) Community widmet. „Wir sind eine Minderheit
innerhalb der Schwarzen Bewegung und eine Minderheit innerhalb der
LGBTQ*-Community“, beschreibt Freeman. Und lobt an re•shape, „dass
es ein sehr niedrigschwelliges Programm ist. Das hilft, wenn du
ohnehin mit vielen Hürden in deinem Leben zu kämpfen hast.“ Im Zuge
des TRAP$ Academy-Projekts ist Wissen über Schwarze Geschichte aus
trans- und genderdiverser Perspektive in Workshops gesammelt
worden, unter anderem entstand daraus ein Arbeitsbuch, das andere
empowern soll, die von Diskriminierung und Rassismus betroffen
sind.
Allen Teilnehmenden standen dabei Mentor*innen zur Seite,
hauptsächlich aus den Communitys der Wikimedia-Projekte. In
verschiedenen Workshop-Formaten gab es Vorträge zum Thema Freies
Wissen und Freie Lizenzen. Auf der unmittelbaren Verwertbarkeit der
Projektergebnisse für Wikipedia oder Wikimedia Commons lag in der
ersten Runde noch nicht der Fokus, künftig wird sich das ändern:
„Welches marginalisierte Wissen Eingang in die Wikimedia-Projekte
finden kann, ist ein gemeinsamer Lernprozess für alle Beteiligten,
in dem wir zusammen das Ziel verfolgen, die Darstellung des Wissens
ausgewogener und gerechter zu gestalten“, beschreibt Dominik
Scholl, Leiter Kultur & Marginalisiertes Wissen bei Wikimedia
Deutschland: „Wir müssen und wollen bei diesem Programm vieles neu
denken.“
Abwägung der Risiken
„Wir haben versucht, den Menschen, mit denen wir arbeiten,
Freiräume und eigene Handlungsmöglichkeiten in Bezug auf Freies
Wissen zu eröffnen“, beschreibt Riham Abed-Ali aus dem
re•shape-Projektteam. Was sie auch betont: Für marginalisierte
Communitys kann das Teilen ihres Wissens mit Risiken verbunden
sein. Ein Beispiel wäre, dass unter Umständen Daten und
Informationen zugänglich werden, „die genutzt werden könnten, um
Menschen zu kriminalisieren – gerade dann, wenn wir von
illegalisierten Perspektiven sprechen.“
Das betrifft beispielsweise ein Projekt wie Mujeres migrantes
invisibles [unsichtbare migrantische Frauen]. Die Verantwortlichen
Antonia Ramos Posto, Yolanda Justina, Nina Becerra und Llanquiray
Painemal Morales bemühen sich um die Sichtbarmachung von
Migrantinnen ohne legalen Aufenthaltsstatus in Berlin. Im Rahmen
des Projekts haben sie Podcasts erarbeitet, die die
Situation dieser undokumentierten Migrantinnen thematisieren. Und
natürlich genau abgewogen, welche Informationen sie preisgeben.
Zu den möglichen Risiken, so Riham Abed-Ali, zähle auch der
Umgang mit Bildern, die unter freier Lizenz veröffentlicht werden –
und die für propagandistische oder andere missbräuchliche Zwecke
verwendet werden könnten.
Foto: Christopher Schwarzkopf
Antikolonialer Raum und
migrantisches Wissen
Trotz dieser Abwägungen ist im Kontext der ersten
re•shape-Ausgabe viel Konkretes entstanden. Wie etwa der
Antikoloniale Raum Köln, ein Projekt von Muriel Gonzales Athenas
und Amdrita Jakupi. In diesem physischen Raum geht es um
Vermittlung des Wissens marginalisierter Communitys – „durch
Literatur, Workshops, Vorträge von Aktivist*innen oder
Wissenschaftler*innen vornehmlich aus der BIPoC-Community“, wie
Jakupi es im Gespräch während der re•shape-Abschlussveranstaltung
beschreibt. Die Zusammenkunft hat alle Teilnehmer*innen noch einmal
in der Geschäftsstelle von Wikimedia Deutschland zusammengeführt,
wo die Projekte bei einem Gallery Walk präsentiert wurden und es
Räume zur Reflexion von Herausforderungen und Learnings gab. Der
Antikoloniale Raum Köln, so Jakupi, „soll ein Begegnungsort und ein
Schutzraum für Menschen sein, die sonst keine Räume haben.“ Für
indigene, kurdische oder afrodiasporische Communitys etwa, für
Rom*nja und Sinti*zze. „Die Förderung durch re•shape hat uns
geholfen, diesen Ort überhaupt zu erschließen und benutzbar zu
machen.“
Um eine konkrete Auseinandersetzung mit der Wikipedia wiederum
ging es in dem Projekt „Social Media und Freie Lizenzen“, das die
Journalistin Esra Karakaya mit ihrem
Medienunternehmen KARAKAYA TALKS unternommen hat. Es produziert
News und Talkshows für deutschsprachige Millennials und Gen Zs of
Color. „Unsere Frage war: Wie können wir Inhalte, die in Videoform
auf TikTok oder Instagram laufen, journalistisch so aufbereiten,
dass sie als Referenzen und Quellenangaben für Wikipedia-Artikel
nutzbar werden?“, beschreibt Karakaya. Im Rahmen von re•shape hat
sie eine Webseite getestet, auf der Videos nun in Form von Texten
veröffentlicht werden sollen. „re•shape war eine wichtige
Unterstützung bei unserem Versuch, migrantisch situiertes Wissen,
das oft nicht dokumentiert ist, eben doch festzuhalten – so dass es
vielleicht in ein Wissensarchiv wie Wikipedia gelangt“, so
Karakaya.
Austausch in der
Ideenwerkstatt
Foto: Christopher Schwarzkopf
Wie können Menschen, die von Rassismus und Diskriminierung
betroffen sind, mit ihrem Wissen und ihren Anliegen innerhalb der
Wikipedia-Community mehr Gehör finden? Dieser Frage widmete sich
eine von Wikimedia organisierte Ideenwerkstatt, bei der einzelne
re•shape-Teilnehmende, aber auch viele weitere Interessierte
zusammen kamen. „Es ging bei der Veranstaltung darum, dass die
Beteiligten selbst Barrieren, aber auch Handlungsmöglichkeiten für
mehr Wissensgerechtigkeit identifizieren“, beschreibt Christopher
Schwarzkopf aus dem re•shape-Projektteam. Über den Austausch im
Rahmen der Ideenwerkstatt ist auch eine filmische Dokumentation entstanden.
„Ich denke, dass die Wikipedia noch vielfältiger werden könnte,
indem man Autor*innen aus marginalisierten Communitys gezielt
anwirbt, durch Veranstaltungen oder Workshops wie diesen“, so eine
Teilnehmende. Wikipedianerin Kritzolina, ebenfalls bei der
Ideenwerkstatt mit an Bord, sieht zwar auch Wissenslücken in der
Online-Enzyklopädie – gerade dort, wo es um Themen außerhalb
Europas geht – betont aber: „Die Wikipedia wird offener, auch für
Wissen, das nicht zum klassischen Herrschaftswissen gehört.“ Eine
Teilnehmende mit uigurischen Wurzeln berichtet davon, dass sie
Vorurteile gegenüber der Wikipedia hatte, vor allem, weil sie dort
viel Wissen über die uigurische Geschichte vermisste. „Ich habe
aber gemerkt, dass man selber sehr viel Wissen einbringen
kann.“
Insgesamt war die Ideenwerkstatt ein lebendiges Plädoyer für
Dialog und offenen Austausch. „Menschen sind bereit, Sachen zu
verändern, auch neue Sachen zu lernen“, bringt eine Teilnehmende es
auf den Punkt.
Ein Instrument der
Vernetzung
Wie soll die Wikipedia im Jahr 2030 aussehen? Auch diese Frage
stand auf der Agenda der Ideenwerkstatt. „Ich kann mir vorstellen,
dass sie sehr, sehr bunt aussehen könnte“, lautete eine der
Antworten, „dass sehr viele Jugendliche sich beteiligen, auch aus
marginalisierten Gruppen.“ „Wir müssen uns mit Wissensproduktion
auseinandersetzen, kritisch hinterfragen: Wer produziert dieses
Wissen? Über wen wird geschrieben, welche Quellen werden genutzt?“,
so wiederum eine andere Teilnehmerin zu der Frage, wie die
Wikipedia auch 2030 noch aktuell und relevant bleiben könne.
„Die Wikipedia ist wie ein Kühlschrank oder ein Wäscheständer –
sie wird im Alltag selbstverständlich genutzt, aber wir denken kaum
darüber nach“, findet Esra Karakaya. Die Teilnahme an re•shape habe
sie zu genau dieser Auseinandersetzung motiviert. Als „sehr offen
im Dialog, sehr unterstützend“ hat Lea Sherin Kübler – beteiligt am
Projekt „Von Träumen und Traumata zu Selbstorganisation und
Widerstand“, bei dem unter anderem ein Zine entstanden ist – die
re•shape-Zeit erlebt. So erzählt sie es am Rande der re•shape
-Abschlussveranstaltung, die wie das gesamte Projekt auch der
Vernetzung und dem Austausch der Geförderten untereinander dienen
sollte – und ihrer Verbundenheit mit den Wikimedia-Projekten. So
konnten einige auch als Teilnehmer*innen für den ersten Wikipedia-Zukunftskongress gewonnen werden.
Foto: Christopher Schwarzkopf
Ein Lernprozess für alle
Beteiligten
Natürlich war die erste Ausgabe von re•shape für alle
Beteiligten auch ein Lernprozess. Bei der anstehenden zweiten Runde
des Programms wird es einige Anpassungen geben. Während im ersten
Programmjahr noch das Prinzip “Open by default” galt, bei dem sich
die Geförderten gegen eine freie Lizenz entscheiden konnten, wenn
es gute Gründe dafür gab, wird die Veröffentlichung der
Projektergebnisse unter einer freien Lizenz nun zur
Fördervoraussetzung. Projektgruppen müssen fortan nicht mehr
ausschließlich aus BIPoC-Personen bestehen, es reicht, wenn die
Mehrheit der Mitglieder BIPoC sind oder Organisationen mehrheitlich
von BIPoC geleitet werden – so wird die Vielfalt der Teilnehmenden
erhöht. Außerdem wird das Mentor*innen-System überdacht, um noch
passgenauer auf die Bedarfe der Geförderten eingehen zu können.
„Wir wollen auch daran arbeiten, das Programm außerhalb Berlins
noch besser zu bewerben und unsere bestehenden Netzwerke
entsprechend zu erweitern“, beschreibt Riham Abed-Ali. Unter
anderem könnten die Verbindungen des entstehenden Antikolonialen
Raums Köln dabei helfen. Und last but not least soll der Fokus noch
mehr auf das große Thema Wissensgerechtigkeit gerichtet werden. Die
Frage, wie konkret die Wikimedia-Projekte zu mehr
Wissensgerechtigkeit beitragen können, wird künftig noch mehr Raum
erhalten.
Eines jedenfalls hat die erste Ausgabe des neuen Förderprogramms
bereits deutlich gezeigt, findet Dominik Scholl: „An einem Programm
wie re•shape besteht großer Bedarf.“
Der Abschlussbericht von re•shape ist hier zu
finden:
Im November 2024 startet re•shape – Ein Wikimedia-Programm
zur Förderung von Wissensgerechtigkeit in das zweite
Programmjahr. Neben einer finanziellen Förderung von bis zu 5.000 €
umfasst das Programm eine ideelle Förderung in Form von Begleitung
und Beratung in der Auseinandersetzung mit Freiem Wissen und in der Umsetzung der
Projekte.
Gefördert werden Projekte, die darauf zielen, marginalisiertes
Wissen von Communitys, die Rassismus erfahren, mehr Raum und
Sichtbarkeit zu verschaffen, indem Projektergebnisse unter einer
Freien Lizenz veröffentlicht werden. Bewerbungen sind vom 15.
August bis 15. September 2024 möglich und können auf Deutsch oder
Englisch eingereicht werden
Du hast Fragen zum Bewerbungsprozess, der Antragstellung oder
bist dir unsicher, ob deine Projektidee zum Programm passt? Dann
melde dich gern bei uns, zum Beispiel indem du in unsere
telefonische Sprechstunde kommst: Du kannst uns während der
Bewerbungsphase jeweils dienstags und donnerstags von 14.00 bis
15.00 Uhr unter der Nummer (030) 577 116 22-0 erreichen. Gern
vereinbaren wir auch individuelle Termine zur Antragsberatung –
auch vor der Bewerbungsphase. Schreib dafür einfach eine Mail an
reshape@wikimedia.de.
Außerdem bieten wir innerhalb des Bewerbungszeitraums am
Dienstag, den 20. August, um 18.30 Uhr via Zoom eine
Online-Infoveranstaltung zum Programm an. Du kannst dich via E-Mail
an reshape@wikimedia.de
bereits jetzt dafür anmelden.
Der „Rosinenbomber“ auf dem Dach des
Deutschen Technikmuseums in
Berlin zählt zu den Wahrzeichen der Stadt. Er erinnert an die
Zeit des Kalten Krieges, an die Blockade der Westsektoren durch die
Sowjets 1948/49, als die Berliner*innen von den Westalliierten mit
Flugzeugen wie diesem aus der Luft versorgt werden mussten.
Natürlich hat die Douglas C-47 Skytrain (so der offizielle
Flugzeugtyp) auch ihren Auftritt in der Wikipedia – von unten
fotografiert in der Abendsonne. Ein majestätisches Bild.
„Hurra, wir leben noch”, stand auf vielen Plakaten der Menschen,
die sich am 12. Mai 1949 vor dem Rathaus Schöneberg versammelt
hatten, um das Ende der Berlin-Blockade zu feiern. Dieses Jubiläum
wird nun auch in der Wikipedia durch die neuen Aufnahmen noch
greifbarer werden: Wenn der „Rosinenbomber“ aus einem noch viel
spektakuläreren Blickwinkel als bisher zu sehen ist. Von oben, aus
der Vogelperspektive fotografiert.
Ein Blick aus 100 Metern
Höhe
Zu verdanken ist das einer außergewöhnlichen Drohnenflugaktion
über das Museum und die Umgebung. Und nicht nur Bilder des
Flugzeugs werden unter freier Lizenz in Wikimedia Commons und der
Wikipedia zur Verfügung stehen – mit Unterstützung von Wikimedia
Deutschland konnte auch ein Indoor-Flug mit einer Drohne im
Deutschen Technikmuseum unternommen werden. Das Museum hat dafür
seine Lokschuppen geöffnet, wo die Dauerausstellung Eisenbahn zu
sehen ist – mit vielen historischen Lokomotiven und anderen
Großobjekten.
Der Wikipedianer Benutzer:Raymond ist Spezialist für
Drohnenfotografie. Er hat aus der Luft unter anderem schon die
Liegenschaften der Stiftung
Preußische Schlösser und Gärten für die Wikimedia-Projekte
abgelichtet, auch in Weimar bei der Klassik
Stiftung und im Archäologischen Park in Xanten
war er schon aktiv. Im vergangenen Jahr ließ er die Drohne über dem
Museum Barberini in Potsdam aufsteigen, wobei auch ein sehenswerter
Film entstanden ist. Jetzt steht er an einem sonnigen Morgen auf
dem Platz vor dem Deutschen Technikmuseum und schaut konzentriert
auf das Display seines Controllers. Die Drohne ist nur noch als
winziger Punkt am Himmel zu sehen. „Ich fliege in 100 Metern Höhe
erst über die Ladestraße und das Hauptgebäude des Deutschen
Technikmuseums, dann über den Rosinenbomber und die U-Bahnstrecke
am Gleisdreieck in Richtung Tempodrom und zurück“, beschreibt
Benutzer:Raymond die Luftroute.
Damit er diesen Flug überhaupt unternehmen kann, haben Holger
Plickert und Christoph Jackel viel Zeit und Arbeit investiert. Die
beiden Projektmanager von Wikimedia Deutschland kümmern sich um
GLAM-Projekte, also Kooperationen verschiedenster Art mit Kultur-
und Gedächtnisinstitutionen wie Museen, Archiven oder Bibliotheken.
„Ein GLAM-Projekt unterstützt Kultur- und Gedächtnisinstitutionen
dabei, ihrem Auftrag nachzukommen, Objekte für kommende
Generationen in digitaler Form zu bewahren. Durch gemeinsame
Projekte mit erfahrenen Wikimedianer*innen können sie mit der
gesamten Welt geteilt und unabhängig erkundet und erforscht
werden”, so Jackel.
Nicht nur haben die Hauptamtlichen von Wikimedia Deutschland
jetzt das Deutsche Technikmuseum für den Drohnenflug gewonnen, sie
mussten auch alle dafür erforderlichen Genehmigungen einholen. „Das
Museum grenzt an eine Bundesstraße, der benachbarte Landwehrkanal
ist eine Bundeswasserstraße, dazu verläuft dort die Hochbahn der
U1/U3 – bei all dem ist Überflug eigentlich verboten“,
erklärt Benutzer:Raymond.
Beantragt werden mussten eine Reihe von Sondergenehmigungen bei
der Luftfahrtbehörde. Entsprechend hat der Wikipedianer neben einem
Ersatzakku für die Drohne und allerlei anderem technischen
Equipment auch eine dicke Mappe mit Dokumenten dabei – nur für den
Fall, dass die Polizei vorbeikommt und nach den Genehmigungen
fragt.
Strategie der
Öffnung
Auch für die Stiftung Deutsches Technikmuseum Berlin ist die
Aktion reizvoll: „Auf diese Weise bekommen wir eine Perspektive auf
unser Haus, die wir sonst nicht hätten“, so Matthias Stier, Leiter
Digitale Strategie im Museum. Der „Rosinenbomber“ – der in
regelmäßigen Abständen von Industriekletterern gereinigt wird, sei
selbst vom Dach des Museums aus nicht in so spektakulärer
Draufsicht zu erleben.
Das Deutsche Technikmuseum will die Bilder von Benutzer:Raymond
auch über die eigenen Kanäle zugänglich machen – und freut sich
über die Verbreitung in der Wikipedia und auf Wikimedia Commons.
„Die Wikimedia-Projekte sind ein wichtiger Anlaufort“, so
Stier.
Generell verfolgt die landeseigene Institution eine Strategie
der Offenheit: „Wir wollen so viele unserer Sammlungsdaten frei
zugänglich machen wie möglich“, beschreibt Stier, „das Thema
CC-Lizenzierung wird bei uns am Haus groß geschrieben.“
Geglückter Flug durch den
Lokschuppen
Christoph Jackel für Wikimedia
Deutschland, CC BY-SA 4.0
Mit der Achtsamkeit eines Wünschelrutengängers bewegt sich
Benutzer:Raymond mit seiner Drohne durch den Lokschuppen 1 des
Deutschen Technikmuseums. Er lässt sie durch das historische
Fürstenportal des Anhalter Bahnhofs an deren Eingang fliegen,
navigiert sie sicher über eine Preußische Tenderlok T3 von 1901 und
eine Güterzug-Dampflok der Graz-Köflacher Bahn aus dem Jahr 1860.
Begleitet von einem steten Piepsen: „Ich schalte selbstverständlich
die Annäherungssensoren der Drohne nicht aus“, erklärt der Pilot.
Schließlich will er mit dem Fluggerät nirgendwo anstoßen. Diese
Indoor-Aktion ist auch für Benutzer:Raymond eine Premiere – die
ohne Probleme glückt.
Am Ende dieses Vormittags sind rund 100 Bilder entstanden, aus
denen der Wikipedianer eine Auswahl trifft, die nach
und nach bei Wikimedia Commons zur Verfügung gestellt wird –
darunter auch die Drohnenfotos der Loks. Er ist zuversichtlich,
dass die fotografierten Objekte „sehr bald ihren Auftritt in der
Wikipedia bekommen.“
Lust bekommen, bei Wikimedia-Projekten
mitzumachen?
Schau doch mal auf unserer Mitmachseite vorbei. Dort findest Du
viele spannende Angebote für den Einstieg in die Wiki-Welt. Alle
Infos gibt es hier:
Die Bundesregierung gibt in ihrer Datenstrategie vom letzten
Jahr die Marschrichtung vor: Mehr Fortschritt durch mehr und
bessere Daten. Die Ausgangslage ist dabei schwierig. Überall fehlt
es an strukturierten Daten in hoher Qualität, um politische
Entscheidungen zu flankieren oder auch umzusetzen. Das Klimageld
konnte nicht ausgezahlt werden, es gibt keinen Überblick über alle
Sozialleistungen und oftmals fehlt es auch am Verständnis darüber,
was eigentlich Daten sind und wer diese pflegt. Die Datenlabore,
die in allen Bundesministerien ab 2021 eingerichtet wurden, sollten
den Ressorts ganz praktisch im Datenmanagement an die Hand gehen.
Leider steht die Finanzierung schon wieder auf der Kippe, kaum dass
sie ihre Arbeit aufgenommen haben. Dabei zeigen erste Erkenntnisse, dass die
Arbeit durchaus sinnvoll ist. Es braucht also dringend mehr
Datenexpertise und mehr Akteure, die mit guten Ideen in diesem Feld
vorangehen. Kann das geplante Dateninstitut diese Hoffnung
erfüllen? In der Entwicklungsphase des Dateninstituts wurde von
politischer Seite immer wieder betont und in Aussicht
gestellt, dass zivilgesellschaftliche Organisationen das
Dateninstitut mit ihrer Expertise und Perspektive mit aufbauen
sollen, zumindest als Teil eines Konsortiums. Wie gut ist das im
Prozess bislang integriert?
Datenpolitik ist
Gesellschaftspolitik. Die Gemeinwohlorientierung muss stark
verankert sein
In den bisher ausformulierten Grobanforderungen für das
Dateninstitut findet eine Gemeinwohlorientierung keine Erwähnung
mehr. Auch wenn es verschiedenen beteiligten
Politikschaffenden weiterhin ein Anliegen sein wird, eine
Gemeinwohlorientierung einzubringen, ist es schwierig, diesen
Auftrag aus der Ausschreibung konkret herzuleiten. Das bedeutet,
dass wir viele Ressourcen einbringen müssten, um uns innerhalb
eines großen Konsortiums mit ressourcenmäßig überlegenen
Beteiligten, die wenig Fokus auf das Gemeinwohl
haben, durchzusetzen. Eine stärkere Gemeinwohlorientierung
geht nämlich oft zulasten der Profitabilität, die für viele sich
beteiligende Unternehmen relevant ist.
Zudem sind wichtige Spielräume schon vorher eingeschränkt, zum
Beispiel ist eine Vorgabe, dass das Dateninstitut spätestens in
fünf Jahren eigene Einnahmen von mindestens 10 Prozent generieren
muss. Entsprechende Geschäftsmodelle sind üblicherweise nicht mit
freiem Wissen vereinbar, denn wo sollen solche Einnahmen herkommen
wenn nicht aus Lizenzierung oder anderen Datenservices?
Rechtssicherheit des
Betreibermodells sticht Ausprobieren von Ideen
Die Ausschreibung macht deutlich, was den beteiligten
Ministerien am wichtigsten ist: Expertise in Gründungsfragen, bei
juristischen Organisationsformen, beim Datenschutz sowie bei der
Entwicklung von Geschäftsfeldern ist hauptsächlich gefragt. Eine
der Überraschungen bei den Ausschreibungsunterlagen ist zudem, dass
die Ministerien nicht nur – wie ursprünglich geplant – eine
Konzeption für ein gutes Dateninstitut suchen, sondern einen
Partner für das praktische Betreiben des Instituts, inklusive
Gründung, Aufbau, Personalrekrutierung. Diese Aussicht ist der
„Hauptgewinn“ für die teilnehmenden Konsortien. Für uns als
zivilgesellschaftliche Organisationen ist das wenig attraktiv:
Aufbau einer Institution als Dienstleistungsauftrag für den
Staat?
Wenig freie Ressourcen, wenig
Planbarkeit
Konzeptionierung, Gründung und Betrieb des Dateninstituts sind
umfangreiche Aufgaben, die viele Personen aus unterschiedlichen
Organisationen binden werden. Für zivilgesellschaftliche
Organisationen wie unsere ist das eine große Herausforderung, da
wir (anders als z.B. Beratungsunternehmen) keine freien Kapazitäten
vorhalten (können). Dies betrifft die zeitintensive Teilnahme
an der Ausschreibung, aber auch den auf fünf Jahre ausgelegten
Betrieb. Die gleichzeitige Ausschreibung von Konzeption, Gründung
und Betrieb ist unseres Erachtens daher nicht
zielführend. Auch der immer wieder verschobene Zeitplan hat
nicht dazu beigetragen, zivilgesellschaftliche Akteur:innen
einzubinden. Beispielsweise wurde nach dem Marktdialog Anfang Juli
2023 eine Ausschreibung „nach der Sommerpause“ angekündigt, die nun
im Mai 2024 kam. Die Anzahl der Menschen mit passender Expertise in
unseren Organisationen ist begrenzt, und wir haben viele laufende
Projekte und Themen, um die wir uns jeweils oft als einzige
zivilgesellschaftliche Organisation kümmern.
Wettbewerbsverfahren kaum
kompatibel mit zivilgesellschaftlicher Kooperation
Die beteiligten Ministerien wünschen sich möglichst
intersektional aufgestellte Konsortien, um vielfältige Perspektiven
der Datenbereitstellung und Datennutzung abzubilden. Das ist sehr
begrüßenswert. Allerdings sind wir eher skeptisch, ob dies durch
die Zusammensetzung der Konsortien zu schaffen ist, oder ob nicht
eher später im laufenden Betrieb des Dateninstituts Partnerschaften
mit unterschiedlichen Akteursgruppen geschlossen werden sollten.
Unsere Erfahrung während der Anbahnung der Ausschreibung war es,
dass insbesondere wirtschaftliche Akteure (z.B.
Beratungsunternehmen) sehr klare Partikularinteressen vertreten
(z.B. Monetarisierung von Services) und für die Antragstellung nur
noch irgendeine zivilgesellschaftliche Organisation suchten. Dass
die Ausschreibung zudem das Vorliegen von ähnlichen Erfahrungen
verlangt, begünstigt zudem größere Unternehmen. Für eine
Beteiligung am Verfahren müssten wir uns entscheiden, in welchem
Konsortium wir uns einbringen, und über Non-Disclosure Agreements
oder Ähnliches zusichern, unser Wissen nur für dieses Konsortium
einzusetzen. Das widerspricht unseren Prinzipien als
Zivilgesellschaft für ein transparentes Verfahren und offene
Diskussion über diese wichtige Phase der Gründung des
Dateninstituts. Deshalb werden wir unsere Expertise öffentlich
allen zur Verfügung stellen, um eine gemeinwohlorientierte
Ausgestaltung des Dateninstituts zu unterstützen. Auch an einem
Austausch mit den Politikschaffenden sind wir weiterhin
interessiert.
Unser Anliegen: Ein
Dateninstitut für die Gesellschaft
Es ist uns ein Anliegen, dass das Dateninstitut die
Bereitstellung und Nutzung von Daten für das Gemeinwohl fördert.
Wir stehen für ein starkes, kompetentes und unabhängiges
Dateninstitut, das Datenpolitik als Gesellschaftspolitik für Alle
verständlich macht; es stellt Strukturen, Prozesse und
Infrastrukturen in den Mittelpunkt, anstatt auf Einzelprodukte und
kurzfristige Lösungen zu setzen; es ergänzt die bestehenden
Organisationen und Strukturen sinnvoll und schärft damit das
Daten-Ökosystem. Wir wünschen uns, dass der weitere Prozess
möglichst transparent ist, damit auch zivilgesellschaftliche
Akteure, die nicht in Konsortien beteiligt sind, eine
gemeinwohlorientierte Ausgestaltung des Dateninstituts begleiten
und unterstützen können.
Der Südwestrundfunk (SWR) und Spiegel berichteten zunächst über die
Neuigkeiten aus Stuttgart. Demzufolge plant man dort nun,
zunächst Abituraufgaben aus Vorjahren und dann auch die alten
Prüfungsaufgaben anderer Schulformen digital und frei zugänglich zu
machen. Alle Schüler*innen können damit unkompliziert auf die
Aufgaben zugreifen. Sie sind nicht darauf angewiesen, dass Schulen
oder Lehrkräfte sie ihnen zur Verfügung stellen und können somit
selbsständig lernen. Zuvor hatte der SWR bereits über unsere Kampagne und
die dazugehörige Petition zur Veröffentlichung
von Prüfungsaufgaben berichtet.
Hat über 54.000 Unterstützer und
Unterstüterinnen – die Petition von FragDenStaat und Wikimedia
Deutschland zur Freigabe von alten Prüfungsaufgaben. Foto:
Screenshot Franziska Kelch (WMDE) CC BY-SA 4.0
Hat über 54.000 Unterstützer und
Unterstüterinnen – die Petition von FragDenStaat und Wikimedia
Deutschland zur Freigabe von alten Prüfungsaufgaben. Foto:
Screenshot Franziska Kelch (WMDE) CC BY-SA 4.0
Die Entscheidung, die Aufgaben nun zu veröffentlichen, habe
nichts mit unserer Kampagne zu tun, sagt das Ministerium. Oder mit
der Petition zur Veröffentlichung von Aufgaben, die weit über
50.000 Unterschriften erhalten hat. Oder mit der
Medienberichterstattung zur Kampagne und zur Petition in diesem und
im letzten Jahr. Die auch thematisiert hat, dass FragdenStaat und
Wikimedia Deutschland aufgedeckt haben, dass auch das
Kultusministerium in Baden-Württemberg Prüfungsaufgaben an Verlage
verkauft, statt sie Schüler*innen einfach digital zur Verfügung zu
stellen. Verlage nutzen diese Aufgaben dann in Übungsheften – die
sich nicht alle Prüflinge leisten können oder wollen.
Aber wir schweifen ab. Zurück zu den guten Nachrichten für
künftige Prüflingsgenerationen in Baden-Württemberg!
Wir begrüßen, dass im Kultusministerium offenbar ein Umdenken
stattgefunden hat und Aufgaben digital und öffentlich zur Verfügung
gestellt werden. Das ist ein Schritt zu mehr Bildungsgerechtigkeit
in Baden-Württemberg. Auch den Umstand, das nicht nur junge
Menschen, die das Abitur machen, sondern Schüler*innen aller
Schulformen Zugang zu Prüfungsaufgaben bekommen sollen, sehen wir
als Fortschritt. Aber es gibt zwei offene Fragen und damit
potenzielle Kritikpunkte.
Was sagt das Ministerium zum
Verkauf der Aufgaben?
Kurz gesagt: Nichts. Zumindest ist der Berichterstattung nichts
dazu zu entnehmen. Das führt uns zu der Frage: Betrifft das
Umdenken im Kultusministerium in Baden-Württemberg auch den Verkauf
der Aufgaben und wird dieser eingestellt?
Aktuell erteilt das Kultusministerium in Baden-Württemberg
mindestens einem Verlag gegen eine Gebühr die Erlaubnis, die
Abschlussaufgaben aller Schulformen zu veröffentlichen. Das ist
leider nicht ungewöhnlich, mindestens neun weitere Bundesländer
verfahren so. Das Kultusministerium in Baden-Württemberg aber
erhält zusätzlich 10% vom Netto-Buchpreis von Lehr- und
Übungsbüchern, die der Verlag verkauft. Nach unserem Wissen ist
Baden-Württemberg damit das einzige Bundesland, das in diesem
Umfang am Verkauf der Hefte beteiligt ist. Wir kritisieren diese
Praxis, denn wir sind der Ansicht, dass mit öffentlichen Mitteln
erstellte Aufgaben nicht monetarisiert, sondern der Öffentlichkeit
zur Verfügung gestellt werden sollten.
Mit Prüfungsaufgaben alleine ist
es nicht getan
Darüber hinaus stellen wir uns die Frage, in welchem Umfang
Prüfungsaufgaben veröffentlicht werden. Denn der Mehrwert von
Prüfungen aus Vorjahren entsteht für Schüler*innen vor allem dann,
wenn sie auch die Lösungen erhalten – oder zumindest die
sogenannten Erwartungshorizonte zu den einzelnen Prüfungen. Denn
nur so wissen sie auch, was von ihnen erwartet wird. Wenn etwa
Schüler*innen aus Niedersachsen sich Abituraufgaben aus den Vorjahren herunterladen, dann
erhalten sie nicht nur die Aufgaben, sondern auch die
Erwartungshorizonte.
Ein weiterer Faktor dafür, wie nützlich die Aufgaben für
Prüflinge sind, ist die Verfügbarkeit von Texten, Statistiken,
Fotos oder Karten, die in der Aufgabe verwendet wurden.
Baden-Württemberg kündigt an, dass solche Drittmaterialien
teilweise aus urheberrechtlichen Gründen geschwärzt und durch
Quellenangaben ersetzt werden. Schleswig-Holstein macht das ähnlich
und schwärzt leider auch Gedichte von
Goethe, die schon seit über hundert Jahren gemeinfrei sind.
In Niedersachsen ist man stärker darum bemüht, die Aufgaben, die
entsprechenden Erwartungshorizonte und
Drittmaterialien zu veröffentlichen. Dafür werden teilweise Texte,
Statistiken oder Bilder genutzt, die gemeinfrei oder frei
lizenziert sind. Oder bei der Entwicklung der Aufgaben werden
digital verfügbare Drittmaterialien genutzt, deren URL dann bei der
Veröffentlichung angegeben wird. So können Schüler*innen häufig
Aufgaben für die Vorbereitung nutzen, die einen großen Mehrwert
haben, weil sie zusätzlich Erwartungshorizonte und Drittmaterialien
enthalten.
Wir sind gespannt, ob sich Baden-Württemberg daran ein Beispiel
nehmen wird. Die Veröffentlichung der Aufgaben ist laut
Berichterstattung für den Oktober geplant.
Gemeinwohl oder auch das öffentliche Interesse sind
wohlklingende Konzepte – und doch abstrakt und
interpretationsoffen. Was es konkret braucht, um Daten für mehr
Gemeinwohl zu nutzen, klärte Aline Blankertz, Referentin für
Politik und öffentlicher Sektor, zu Beginn ihrer Stellungnahme
gegenüber den Digitalpolitiker*innen in Berlin.
Grafik: Franziska Kelch (WMDE), CC BY-SA
4.0
Grafik: Franziska Kelch (WMDE),
CC BY-SA 4.0
Weniger Innovationshype und mehr
gesellschaftlicher Nutzen
„Innovative Datenpolitik: Potenziale und Herausforderungen“, so
lautete das Thema der Anhörung im Digitalausschuss des Bundestages.
Und auch zahlreiche Fragen aus dem Katalog, der an die
Sachverständigen geschickt wurde, machten deutlich: Auf politischer
Ebene herrscht die Vorstellung, dass Daten ein oder sogar der Motor
für Innovationen sein sollen und können. Es gibt aktuell geradezu
einen Innovationshype, also einen übersteigerten Glauben an
Innovation. Dabei braucht es an vielen Stellen gar keine
technologischen Neuerungen, um gesellschaftliche Probleme zu
adressieren. Wir brauchen vielmehr eine konsequente Nutzung von
bekannten und bewährten Konzepten und Prozesse. Das zeigt sich am
Beispiel der öffentlichen Verwaltung. Der mangelt es aktuell an
einer soliden Datenarchitektur und -infrastruktur. Die brauchen
Behörden, um effizienter zu werden – und nicht etwa “Künstliche
Intelligenz”. Beim Reden über Innovationen wird gerne vergessen,
dass wir den zweiten Schritt nicht vor dem ersten machen sollten.
Und der erste Schritt, nämlich die technischen und personellen
Grundlagen der Verwaltungsdigitalisierung zu schaffen, ist noch
nicht einmal vollzogen.
Wenn wir Innovation schaffen, sollte wir uns daran orientieren,
was gesellschaftlich nützlich ist. Das ist oft nicht das, was
wirtschaftlich besonders profitabel ist. Das ist eine
Herausforderung. Denn digitale Infrastrukturen liegen überwiegend
in der Hand weniger, mächtiger Digitalkonzerne. Diese verfolgen
nicht das Gemeinwohl als Ziel. Oft schaden sie der Gesellschaft
sogar, zum Beispiel indem sie Desinformationen verbreiten, sich die
Wertschöpfung von Kreativen und Journalist*innen aneignen, oder
durch schlechte Arbeitsbedingungen und Überwachung. Wir müssen die
Gemeinwohlorientierung von Plattformen, digitalen Dienstleistungen
oder KI-Anwendungen stärken, indem die Politik gesellschaftlichen
Interessen mehr Gewicht gibt. Das kann durch Zerschlagung oder
Regulierung geschehen. Aber auch, indem die öffentliche Hand selbst
in digitale Strukturen investiert und diese aufbaut und dauerhaft
pflegt.
Für mehr Datenzugang und weniger
Geschäftsgeheimnisse
Wenn wir mehr Daten besser für Innovationen nutzen wollen, die
in erster Linie einen gesellschaftlichen Nutzen haben, dann ist der
Zugang zu Daten entscheidend. Und ein wesentlicher Teil von Daten
zu A wie Automobilität bis Z wie Zahlungsverkehr liegt in den
Händen von Unternehmen. Eine der größten Hürden für einen breiten
Zugang und eine Nutzung dieser Daten im öffentlichen Interesse ist
der Geschäftsgeheimnisschutz.
Wenn es darum geht, den Geschäftsgeheimnisschutz zu verteidigen,
hört man oft ein vermeintliches Argument: Wenn Unternehmen Daten
nicht exklusiv nutzen können, dann ginge der Anreiz verloren, diese
überhaupt zu erheben. Was dabei ignoriert wird: Das
Geschäftsgeheimnis verlangsamt die Verbreitung von Wissen – oder
unterbindet sie komplett. Denn es gilt zeitlich unbegrenzt. In
einer Wissensgesellschaft können Geschäftsgeheimnisse damit zum
Hemmschuh von Innovation und Wettbewerb werden. Dementsprechend
sollte der Gesetzgeber beim Ausmaß des Geschäftsgeheimnisschutzes
abwägen zwischen Anreizen auf der einen und Wissensverbreitung auf
der anderen Seite.
Außerdem sollten Gemeinwohlaspekte in die Abwägung einbezogen
werden. Besonders deutlich wird dies bei einem Gemeingut, das in
unser aller Interesse liegt: Die Umwelt. Mehr Datenzugang kann
dabei helfen, Produkte ökologisch verträglicher herzustellen, zu
nutzen und wiederzuverwerten. Ein Beispiel dafür, wie das in der
Praxis funktionieren kann, ist die Ecodesign for Sustainable
Product Regulation (ESPR) auf EU-Ebene. Sie führt digitale
Produktpässe ein, um die Kreislaufwirtschaft zu stärken. Der neue
Produktpass wird Informationen über die ökologische Nachhaltigkeit
durch Einscannen eines Datenträgers leicht zugänglich machen. Die
enthaltenen Daten sollen Auskunft geben über die Haltbarkeit und
Reparierbarkeit, den Recyclinganteil oder die Verfügbarkeit von
Ersatzteilen eines Produkts. So sollen Verbraucher und Unternehmen
besser fundierte Kaufentscheidungen treffen können. Produktpässe
sollen zudem Behörden helfen, Kontrollen und Prüfungen besser
durchzuführen. Hersteller müssen also möglichst viele Daten für
diese Zwecke bereitstellen, auch wenn manche Datenpunkte für
Hersteller betriebswirtschaftlich wertvoll sind. Die Pässe können
perspektivisch auch nützlich sein, wenn es darum geht, höhere
Umweltstandards festzuschreiben und zu überprüfen. Denn über die
Pässe würden Daten darüber vorliegen, inwiefern Produkte gerade
umweltverträglich sind – oder nicht. Das kann politischen
Akteur*innen als Grundlage dafür dienen zu entscheiden, welche
Vorgaben oder Standards sinnvoll und effektiv sind.
Bei der Ausgestaltung von Datengesetzen und in neuen
Gesetzgebungsverfahren müssen wir klarstellen, dass
Geschäftsgeheimnisse keine Trumpfkarte sein dürfen, sondern
abgewogen werden müssen. Das gilt etwa für das
Forschungsdatengesetz, die nachgelagerten Verordnungen zur ESPR,
das Mobilitätsdatengesetz und so weiter. Zweitens, wir brauchen
ausdrücklich Pflichten, um mehr Datenzugang zu ermöglichen. Dass
Anreize nicht funktionieren, zeigt die aktuelle Situation.
Bundestransparenzgesetz: Das
wichtigste datenpolitische Vorhaben fehlt bisher
Man fühlt sich ein bisschen wie der Wetteransager Phil Connors,
der in „Und täglich grüßt das Murmeltier“ in einer Zeitschleife
gefangen ist und immer und immer wieder den gleichen Tag erlebt.
Denn immer und immer wieder betonen Wikimedia Deutschland,
zahlreiche andere Organisationen und Akteur*innen: Wir brauchen
dringend ein Transparenzgesetz. Das ist breiter Konsens. Das
Transparenzgesetz und das Recht auf Open Data sind die wichtigsten
Datenvorhaben für diese Legislaturperiode. Doch sie stecken
irgendwo im BMI fest.
Im Bündnis Transparenzgesetz engagieren
wir uns mit neun weiteren Organisationen seit Jahren dafür, dass
die Bundesregierung endlich ein Bundestransparenzgesetz
verabschiedet. Zuletzt haben wir eine Petition gestartet, um
Politikschaffenden zu verdeutlichen, dass viele Menschen diese
Forderung unterstützen. Übergeben haben wir die Petition dann an
Akteur*innen aus dem verantwortlichen Ministerium und aus
Bundestagsausschüssen – hier etwa an Misbah Khan (Bündnis90/Die
Grünen und Mitglied im Digitalausschuss und im Ausschuss für
Inneres und Heimat, 2.v.l.) und Konstantin von Notz (Bündnis90/Die
Grünen, Mitglied im Ausschuss für Inneres und Heimat, 2.v.r.) Beide
befürworten ein Bundestransparenzgesetz. Foto: Mehr Demokratie e.V.
CC BY-SA 2.0
Im Bündnis Transparenzgesetz
engagieren wir uns mit neun weiteren Organisationen seit Jahren
dafür, dass die Bundesregierung endlich ein Bundestransparenzgesetz
verabschiedet. Zuletzt haben wir eine Petition gestartet, um
Politikschaffenden zu verdeutlichen, dass viele Menschen diese
Forderung unterstützen. Übergeben haben wir die Petition dann an
Akteur*innen aus dem verantwortlichen Ministerium und aus
Bundestagsausschüssen – hier etwa an Misbah Khan (Bündnis90/Die
Grünen und Mitglied im Digitalausschuss und im Ausschuss für
Inneres und Heimat, 2.v.l.) und Konstantin von Notz (Bündnis90/Die
Grünen, Mitglied im Ausschuss für Inneres und Heimat, 2.v.r.) Beide
befürworten ein Bundestransparenzgesetz. Foto: Mehr Demokratie e.V.
CC BY-SA 2.0
Dabei ist Transparenz nötig, damit staatliche Stellen
rechenschaftspflichtig bleiben. Sie ist eine notwendige
Voraussetzung, um Politik und Verwaltung in ihrem Handeln für die
breite Gesellschaft transparenter zu machen. Transparenz ist
außerdem ein Grundstein für eine effektive Verwaltung und eine
solide Dateninfrastruktur.
Bundesbehörden und Ministerien erheben und besitzen
Emissionsdaten, Geodaten, Haushaltsdaten, soziodemographische
Daten. Mobilitätsdaten und viele weitere mehr. Diese als Open Data
zur Nachnutzung verfügbar zu machen, hätte zwar auch einen
wirtschaftlichen Mehrwert. Offene Daten aus den Behörden und
Ministerien können aber vor allem eine Grundlage für eine
effizientere Verwaltung sein. Die bestehenden Transparenzgesetze
und Transparenzportale in Hamburg oder Rheinland-Pfalz
beispielsweise werden zu einem großen Teil von Behörden selbst
genutzt. Denn sie selbst gehören zu den größten Nutznießern der
Daten von anderen Verwaltungsteilen. Die Bereitstellung offener
Daten durch die Verwaltung nützt also auch den jeweils anderen
Behörden innerhalb der Verwaltung. Sie trägt dazu bei, dass
Prozesse effizienter werden. Die automatische Bereitstellung von
Linked Open Data sollte dabei das Zielbild sein, damit die Daten
möglichst verknüpft und barrierearm genutzt werden können. Eine
konsequent nach den anerkannten Regeln der Technik digitalisierte
Verwaltung schafft nicht nur die Grundlage für Vorhaben wie den
Onlinezugang zu Dienstleistungen, sondern sorgt dabei auch für
Transparenz und verknüpfbare Register.
Herzlichen Glückwunsch an Alice Wiegand! Sie wurde auf der
heutigen Mitgliederversammlung in Berlin mit 379 Stimmen in ihrem
Amt als Präsidiumsvorsitzende bestätigt. Alice Wiegand ist bereits
seit 2004 in der Wikipedia aktiv und hatte in den vergangenen zwei
Jahrzehnten unterschiedliche Wikimedia-Ämter inne, unter anderem im
Vorstand des Vereins sowie als Mitglied im Board of Trustees der
Wikimedia Foundation. Vor zwei Jahren wurde sie von den Mitgliedern
zur Vorsitzenden des Präsidiums ernannt.
Zur neuen Schatzmeisterin wählten die Mitglieder Friederike von
Borries. Die Beisitzer*innen des 9. Präsidiums sind Larissa Borck,
Valerie Mocker, Nora Circosta, Kamran Salimi und Jens Ohlig.
Außerdem wurden mit Axel Zehrfeld und Andreas Ettwig zwei der vier
Kassenprüfer*innen des Vereins neu gewählt.
Mitglieder diskutieren über
Zukunft von Wikimedia und Wikipedia
Foto: Jason Krüger, CC BY-SA 4.0
Vor der offiziellen Mitgliederversammlung fand in Berlin ein
offenes Austauschformat zur Zukunft von Wikimedia und den
Projekten, allen voran Wikipedia, statt. Rund 80 Mitglieder nahmen
daran teil. Dabei wurden insbesondere die Grundfragen des ersten
Wikipedia-Zukunftskongresses aufgegriffen, der vor zwei Wochen
in Nürnberg stattfand: Was soll sich verändern, was soll bleiben
und warum wollen wir weitermachen?
Bei dem Austausch kristallisierten sich mehrere Schwerpunkte
heraus. Einer davon ist der Wunsch, den Einstieg in die
Wikipedia-Arbeit für neue Freiwillige noch attraktiver zu
gestalten, beispielsweise durch niedrigschwellige und leichter
verständliche Onboarding-Angebote und eine offenere
Willkommenskultur.
Wie schon in Nürnberg spielte auch in Berlin die Frage nach dem
Umgang mit Künstlicher Intelligenz eine große Rolle. Unter den
Mitgliedern gab es bei diesem Thema von “gesunder Skepsis” bis hin
zu “Wir müssen viel verändern, um relevant zu bleiben” eine ganze
Bandbreite an Meinungen. Alle Ideen und Anregungen, wie
beispielsweise für ein eigenes KI-Programm, das ausschließlich mit
Daten aus Wikipedia und Wikidata arbeitet, wurden gesammelt und
werden jetzt aufbereitet. Auch auf der WikiCon im Oktober steht die
Frage nach der Zukunft der Wikipedia noch einmal im Fokus. Mitte
Oktober werden dann in einem Online-Format nächste Schritte
identifiziert, danach geht es an die konkrete Umsetzung der
Ideen.
Alle Ergebnisse des ersten Wikipedia-Zukunftskongresses sowie
die Aufzeichnungen der Vorträge und Podiumsdiskussionen gibt es zum
Nachsehen und Nachlesen hier.
Großes Fest zum 20.
Jubiläum
Am Vorabend der Mitgliederversammlung wurde das 20. Jubiläum von
Wikimedia Deutschland gebührend gefeiert. In der Geschäftsstelle
des Vereins in Berlin kamen Mitarbeitende, Mitglieder, Spendende
und zahlreiche Wegbegleiter*innen zusammen. Einen Rückblick gibt es
in Kürze auf unserer Geburtstagsseite unter wikimedia.de/20jahre. Ein Besuch lohnt sich, die Seite
bietet viele Highlights, unter anderem eine Zeitreise durch die
vergangenen 20 Jahre mit spannenden Meilensteinen, Fotos und
Audioaufnahmen von Menschen, die live mit dabei waren. Außerdem
sind viele Glückwünschvideos zu sehen, unter anderem von
Wikipedia-Gründer Jimmy Wales.
Liebe Anwesende, wir haben uns heute hier versammelt, um Abschied
zu nehmen von einem Projekt, das die Welt des Wissens
revolutioniert hat. Abschied von einer Idee, die Millionen Menschen
inspiriert und zusammengebracht hat. Abschied von der
Wikipedia.
Elisabeth Mandl,
Kommunikationsmanagerin Neue Ehrenamtliche
Mit dieser Trauerrede eröffnet Moderatorin Elisabeth Mandl den
Wikipedia-Zukunftskongress. Natürlich eine satirische Zuspitzung –
Totgesagte leben bekanntlich länger! Wobei den Teilnehmenden des
ersten Wikipedia-Zukunftskongresses bewusst ist, dass sich die
Online-Enzyklopädie weiterentwickeln muss, um relevant zu bleiben.
Wie genau – das wurde drei Tage lang vor Ort in Nürnberg und online
diskutiert.
Post-enzyklopädischer
Schwanengesang: Der veränderte Umgang mit Wissen
Das Programm des Zukunftskongresses beschrieb drei zentrale
Herausforderungen für die Wikipedia: den veränderten Umgang mit
Wissen, den technischen Wandel sowie die Veränderung der
Community.
Das Podium „Informationen teilen, Wissen
erschließen – welche Rolle spielt die Wikipedia?“ mit (von links
nach rechts) Christian Pentzold, Bernd Fiedler, CaroFraTyskland,
Chris Tedjasukmana und Sinthujan Varatharajah. Foto: Steffen
Prößdorf, CC BY-SA 4.0 , via Wikimedia Commons
Zur Frage, wie sich unser Umgang mit Wissen verändert, hält
Chris Tedjasukmana, Professor für Alltagsmedien der Universität
Mainz, einen Vortrag unter dem Titel „Unordentliche
Wissenspraktiken“. Seine Kernthese: Wissen erscheint heute
fragmentiert und in allen möglichen Kontexten im digitalen Raum.
Tedjasukmana spricht von „post-enzyklopädischen Wissens-Kulturen“.
Das Konzept der Wikipedia, Wissen an einem festen Ort zu bündeln,
könnte dadurch überholt werden. Wikipedia-Inhalte stecken zwar
überall – sie sind Grundlage von KI-Anwendungen, Sprachassistenten
und TikTok-Videos – aber die Plattform selbst wird immer weniger
wahrgenommen.
Eine Prognose, die der Medientheoretiker Christian Pentzold auf
dem anschließenden Panel etwas entschärft: „Wenn neue Arten von
Medien auf der Bildfläche erscheinen und sich durchsetzen, heißt
das nicht zwangsläufig, dass alte Medienformen verschwinden. Ihnen
wird nur ein neuer Platz zugewiesen.“ Wikipedianerin
CaroFraTyskland gibt zu bedenken, dass mit sinkenden
Leser*innen-Zahlen auch die Motivation der Community sinken könnte,
sich weiter zu engagieren. Pentzold bleibt optimistisch: „Die
Wikipedia lebt und atmet – und bleibt allein dadurch relevant.“
Grüße aus dem Silicon Valley:
Der gegenwärtige technologische Wandel
Ein omnipräsentes Thema auf dem Kongress waren die
technologischen Entwicklungen rund um Künstliche Intelligenz (KI) –
auch im Eröffnungsvortrag des deutschen Informatikers Richard
Socher, der als KI-Koryphäe live aus dem Silicon Valley
zugeschaltet war. Socher, CEO von you.com, einem neuen
Chat-Suchassistenten, sprach über die Möglichkeiten moderner
Large Langue Models (LLMs), die
Antworten in Form von Texten, aber auch von Graphen oder Diagrammen
liefern können. Sein Vorschlag: ein LLM ausschließlich mit
Wikipedia-Daten zu programmieren, um möglichst präzise KI-Antworten
zu erhalten. Socher dankte abschließend den versammelten
Community-Mitgliedern für ihren großartigen Dienst „im Namen der
Menschheit“.
Das Podium „Handschrift, Buchdruck, WWW –
und was kommt dann?“ mit (von links nach rechts) Franziska Heine,
Kurt Jansson, Theresa Züger, Carina Zehetmaier, Hannah Monderkamp
und Marcus Richter. Foto: Steffen Prößdorf, CC BY-SA 4.0 , via
Wikimedia Commons
Theresa Züger, Leiterin der Nachwuchsforscher*innengruppe Public
Interest AI, gab einen Einblick in die Hintergründe von Künstlicher
Intelligenz und beleuchtete die Herausforderungen, die damit
einhergehen. Zum Beispiel Datenschutzprobleme, mangelnde
Transparenz oder die fehlende Trennschärfe zwischen KIs, die neues
Wissen generieren – und solchen, die lediglich vorhandenes Wissen
replizieren. Ihre Schlussfolgerung: Die Wikipedia werde eine
wichtige, vertrauenswürdige Wissensbasis bleiben, die von KI nicht
ersetzt werden kann.
Welche Rolle die Wikipedia selbst bei der Entwicklung von KI
spielt, darüber wurde auf dem Panel „Handschrift, Buchdruck, WWW –
und was kommt dann?“ diskutiert. Theresa Züger betont den Wert von
Wikipedia-Daten, die oft von großen Unternehmen genutzt würden,
ohne sich dafür erkenntlich zu zeigen. In welcher Form so eine
Gegenleistung erbracht werden könne, darüber werde gegenwärtig viel
diskutiert, so Franziska Heine, Vorständin von Wikimedia
Deutschland.
Einig waren sich die Panelist*innen darin, dass es
interdisziplinäre Teams braucht, die Bias in KI-generierten Daten
erkennen. Und dass Tools zur Unterstützung der Wikipedia-Community
entwickelt werden müssten, die beispielsweise beim Faktencheck und
der Bekämpfung von Vandalismus unterstützen.
Für Online-Communitys und ihre Dynamiken ist der
Kulturwissenschaftler Daniel Sigge ein Experte. Auf dem
Zukunftskongress gibt er Einblicke in die Entstehungsgeschichte
dieses sozial-digitalen Phänomens und stellt ein
Lebenszyklus-Modell von Communitys in verschiedenen Phasen ihres
Bestehens vor. Sigges konkrete Empfehlungen für eine neue Strategie
der Wikipedia-Community: sich von der Vergangenheit zu lösen, an
der Gegenwart zu orientieren und spielerisch auf das zu
konzentrieren, was kommt.
Das Podium „Zwischen Tradition und
Innovation – wie entwickelt sich die Wikipedia-Community?“ mit (von
links nach rechts) Sonja Fischbauer, Martin Gerlach, Daniel Sigge,
Jan Krewer und DomenikaBo. Foto: Steffen Prößdorf, CC BY-SA 4.0 ,
via Wikimedia Commons
Jan Krewer, Senior Policy Analyst bei Open Future, rät der
Wikipedia-Community auf dem anschließenden Panel ebenfalls, sich
von den Anfängen als sozial-politische Bewegung zu emanzipieren und
über die Online-Enzyklopädie aktuelle Themen zu besetzen,
beispielsweise mehr Expert*innenwissen zur Klimakrise einzubinden.
Wikipedianerin DomenikaBo regt an, sich auch auf technischem Gebiet
neuen Trends zu öffnen. Zum Beispiel könne die Wikipedia-App so
weiterentwickelt werden, dass sich Bearbeitungen leichter auf dem
Smartphone durchführen lassen.
Zur Frage, wie sich Wachstum und Diversität der Community
fördern ließen, gibt Sigge zu bedenken, vielen Lesenden sei noch
immer nicht klar, dass Wikipedia ein Mitmach-Projekt ist. Aus dem
Publikum wird angemerkt, die deutsche Wikipedia-Community sei
tendenziell streng gegenüber Wandel und Neulingen und tendiere dazu
„Burgen zu bauen“. Deshalb wären eine offene Willkommenskultur und
das Motto „Spread more Wikilove“ ein guter Ansatz für die Zukunft,
findet DomenikaBo.
Alice Wiegand, Vorsitzende des deutschen Wikimedia-Präsidiums,
ermuntert die Community nach intensiver dreitägiger Diskussion
schließlich, die vielen Impulse auch wirklich zu nutzen.
Entsprechend wurden in drei Online- und vier Präsenz-Workshops
konkrete Fragen ausgehandelt. Zum Beispiel: Welche Veränderungen
sind gewünscht – und was an der Wikipedia soll beim Alten
bleiben?
Einigkeit besteht darin, dass die deutschsprachige Wikipedia im
Kern genau die hochwertige freie Enzyklopädie mit einer
leidenschaftlichen Community bleiben soll, die sie ist.
Teilnehmer*innen des
Wikipedia-Zukunftskongress bei einem Workshop. Foto: Steffen
Prößdorf, CC BY-SA 4.0 , via Wikimedia Commons
Demgegenüber stehen viele Ideen für Veränderungen, die in
verschiedenen Workshops am letzten Tag des Zukunftskongresses
gesammelt wurden – und die viele Impulse aus den Keynotes und
Panels wieder aufgriffen: KI-Tools etwa könnten gerade
Neu-Autor*innen den Einstieg in die Wikipedia-Arbeit erleichtern,
Übersetzungen von Texten in andere Sprachversionen erstellen,
Schaubilder erzeugen oder auch helfen, Wikipedia-Versionen in
einfacher Sprache zu erstellen, ohne dabei den Menschen überflüssig
zu machen, der die Informationen verlässlich aufbereitet.
Viele der Teilnehmenden wünschen sich auch, dass mehr
marginalisiertes Wissen und diversere Perspektiven Eingang in die
Wikipedia finden. Die Wikipedia stärker mit der Gesellschaft zu
verbinden, sich stärker mit Menschen und Organisationen zu
vernetzen, die als Expert*innen Wissen zu den verschiedensten
Feldern beitragen können, ist ein weiterer Punkt, der unter der
Leitfrage „Was wollen wir unbedingt ändern?“ mehrfach genannt
wurde. Außerdem sollen Lesende der Wikipedia in alle Überlegungen
stärker mit einbezogen werden und das Vertrauen innerhalb der
Community, aber auch zwischen der Wikipedia-Community und Wikimedia
soll gestärkt werden.
All diese Punkte werden von der Community und Wikimedia
Deutschland in den kommenden Monaten weiter diskutiert, unter
anderem bei der Wikimedia-Mitgliederversammlung im Juni und auf der
WikiCon im Oktober. Mitte Oktober werden dann in einem
Online-Format nächste Schritte identifiziert. Danach geht es an die
konkrete Umsetzung der Ideen. Inspiriert vom Zukunftskongress hat
sich bereits die Arbeitsgruppe WikiProjekt KI und Wikipedia
gebildet.
Klar wird bei all dem: Die Wikipedia lebt – und sämtliche ihrer
Mitstreiter*innen sind bereit für den Aufbruch in die Zukunft!
Im Vorfeld des Zukunftskongresses haben wir Menschen aus der
Netzwelt nach ihrer Vision für die Wikipedia der Zukunft
gefragt:
Wer den Zukunftskongress in voller Länge oder einzelne Beiträge
und Panels komplett nachverfolgen möchte, findet ab dem 21.6. die
Ergebnisse und die Aufzeichnungen hier:
Verantwortlich für die Ausarbeitung des Gesetzes ist das
Bundesinnenministerium. Das hat bisher jedoch keinen
Referentenentwurf vorgelegt. Doch wenn es vor dem Ende der
Legislatur noch etwas werden soll mit dem Gesetz, dann ist jetzt
Eile geboten. Und 51.582 Unterschriften, die bis zum
Ende der Petition im Juni zusammen kamen, sprechen eine klare
Sprache: Neben den Partnerorganisationen im „Bündnis Transparenzgesetz“ fordern viele Menschen,
dass die Bundesregierung endlich das im Koalitionsvertrag
angekündigte Bundestransprenzgesetz realisiert. Alleine in der
ersten Woche nach Veröffentlichung unterzeichneten über 20.000
Menschen unseren Aufruf bei openPetition.
Die Petition haben wir nun an Abgeordnete von SPD, Grünen und
FDP übergeben. Das Ziel: Sie sollen uns dabei unterstützen, den
Druck auf das zuständige Ministerium zu erhöhen.
Auch Anna Kassautzki (SPD,
Stellvertretende Vorsitzende im Ausschuss für Digitales, 3.v.l.)
und Carmen Wegge (SPD, Mitglied im Ausschuss für Inneres und im
Rechtsausschuss, 3.v.r.) nahmen unsere Petition für ein
Bundestransparenzgesetz entgegen. Foto: Mehr Demokratie e.V. CC
BY-SA 2.0
Auch Anna Kassautzki (SPD,
Stellvertretende Vorsitzende im Ausschuss für Digitales, 3.v.l.)
und Carmen Wegge (SPD, Mitglied im Ausschuss für Inneres und im
Rechtsausschuss, 3.v.r.) nahmen unsere Petition für ein
Bundestransparenzgesetz entgegen. Foto: Mehr Demokratie e.V. CC
BY-SA 2.0
Was bringt ein
Transparenzgesetz?
Für Bürger und Bürgerinnen, die an dem Wissen teilhaben wollen,
das Ministerien beauftragen oder selbst erstellen, erleichtert ein
solches Gesetz den Zugang. Sofern geregelt ist, dass diese
Informationen proaktiv und digital zur Verfügung gestellt werden
müssen. Dazu gehört auch, dass möglichst wenige Ausnahmen im Gesetz
definiert werden. Dort, wo Informationen nicht frei und digital
zugänglich sind, muss zumindest deren Beantragung einfach und
kostenfrei möglich sein und die Beantwortung schnell erfolgen.
Im Bündnis setzen wir uns daher dafür ein,
dass Verträge über 100.000 EUR, Gutachten und Studien sowie
Subventionszahlungen aktiv offengelegt werden. Dabei mögen nicht
alle Gutachten für alle Bürger und Bürgerinnen relevant sein. Doch
in den über 700 Studien und Gutachten,
die nur in den ersten zwei Jahren der aktuellen Legislatur von
Bundesbehörden und Ministerien in Auftrag gegeben wurden,
schlummert viel Wissen.
Für Journalistinnen und Journalisten bedeutet ein
Transparenzgesetz, dass sie leichter Zugang zu Informationen über
ministerielle Vorgänge, Abstimmungen in Behörden oder Verträge mit
externen Dienstleistenden erhalten. Das erleichtert journalistische
Recherchen, die das Handeln von Behörden für die Öffentlichkeit
nachvollziehbar machen, aber auch die Kontrolle staatlichen
Handelns durch die vierte Gewalt.
Erste Auswertungen von Transparenzgesetzen
in einzelnen Bundesländern zeigen auch: Das Vertrauen in
staatliche Instanzen steigt dort, wo diese offenlegen, wie sie
arbeiten und ihr Wissen teilen. Und auch die Verwaltungen selbst –
die oft behaupten, Transparenzgesetze bedeuten für sie einfach nur
mehr Arbeit – können profitieren. Die Evaluation des
Transparenzgesetzes in Hamburg hat gezeigt, dass ein großer Teil
der Anfragen auf dem Transparenzportal von Behörden selbst stammt.
Der Informationsfluss zwischen öffentlichen Stellen wird also
besser. Die Erhebungen aus Hamburg und auch aus Rheinland-Pfalz
weisen darauf hin, dass mehr Transparenz Behörden keinesfalls
hemmt, sondern sogar effizienter machen kann.
Und auch freie Wissensprojekte wie die Wikipedia können von
einem Bundestransparenzgesetz profitieren. Denn immer wieder geben
Bundesbehörden oder Ministerien Studien oder Gutachten in Auftrag.
Sie produzieren also Wissen. Sofern dies öffentlich zugänglich ist,
kann es auch Eingang in enzyklopädische Artikel finden.
Nun ist es am Bundesinnenministerium, endlich einen Entwurf
vorzulegen, damit dieser auch öffentlich diskutiert werden kann.
Einen eigenen Entwurf hat das Bündnis Transparenzgesetz bereits
2022 vorgelegt. Wie dringend eine Umsetzung des Vorhabens ist, hat
die gemeinsame Petition noch einmal verdeutlicht.
Wir stellen uns das Internet als einen vernetzten öffentlichen
Raum vor, in dem Menschen aus aller Welt miteinander kommunizieren,
Informationen und Wissen austauschen und gemeinsam Entscheidungen
treffen können. Wir sind davon überzeugt, dass die Vision eines
offenen, freien, verlässlichen und sicheren Internets mit
innovativen Entwicklungen, die reale gesellschaftliche Bedürfnisse
befriedigen, nur gelingen kann, wenn sich der politische Fokus dem
Gemeinwohl widmet. Daher muss die EU zwingend demokratische
Strukturen, digitale Gemeingüter und die Rechte der
Internetnutzenden fördern und bewahren.
Gesetze gut umsetzen
Die Europäische Union hat in den letzten fünf Jahren wichtige
Regelsetzungen in der Digitalpolitik verabschiedet. Der Macht von
Big Tech und schrankenlosen profitorientierten Interessen wurden
mit dem Digital Services Act (DSA), dem AI Act und dem Digital
Markets Act wichtige Grenzen gesetzt. Diese Gesetze gilt es nun
konsequent umzusetzen. Mit dem DSA wollen die europäischen
Gesetzgebenden dafür sorgen, dass sich jeder Mensch im Netz freier
und ohne von Hass bedroht zu sein, bewegen kann. Dafür müssen
Plattformen den Nutzenden bessere Beschwerdemöglichkeiten geben,
wenn die ihre Recht auf einer Plattform verletzt sehen. In jedem
Mitgliedsland der EU muss nun ein nationaler Koordinator für solche
Beschwerden benannt sein – der sogenannte Digital Services
Coordinator. Wir möchten sicherstellen, dass dieser Koordinator
nicht nur auf dem Papier existiert, sondern auch ausreichend viele
Mittel und personelle Ressourcen erhält, um Beschwerden auch
wirksam entgegennehmen und bearbeiten zu können.
Gemeinwohlorientierte Projekte
fördern
Digitale Gemeingüter, eine öffentliche digitale Infrastruktur
und frei zugängliche und nutzbare Daten sollten als Grundpfeiler
eines europäischen gemeinwohlorientierten öffentlichen digitalen
Raumes substantiell gestärkt werden. Denn dezentralisierte,
durch Gemeinschaften getragene und nicht-kommerzielle Projekte wie
Wikipedia, Open Access, OpenStreetMap, Blender.org, die
Programmiersprache Python und unzählige freie Software-Projekte
vermehren Wissen oder stellen Anwendungen bereit, die der
Gemeinschaft zur Verfügung stehen. Diese digitalen Gemeingüter
tragen dazu bei, dass Internetnutzende nicht vollkommen von
kommerziellen Produkten abhängig sind. Da diese Projekte nicht auf
Profitorientierung angelegt sind, können sie den realen Nutzen in
den Vordergrund stellen – statt beispielsweise die Verweildauer von
Nutzenden zu verlängern, indem sie Algorithmen einsetzen, die
besonders polarisierende Inhalte bevorzugen. Darüber hinaus
basieren diese Gemeinschaftsprojekte auf internen
Aushandlungsprozessen, die in der Regel demokratisch ausgestaltet
sind. Dadurch tragen sie dazu bei, Menschen zusammenzubringen und
eine gesunde Gemeinschaft zu stiften. Wikimedia Deutschland als
eine Bewegung, die erfolgreich gemeinschaftsgetragene Projekte
unterstützt, bietet an, zukünftige Gesetzesvorhaben mit einem
„Wikipedia-Test“ daraufhin zu prüfen, welchen Effekt sie auf
solche Projekte haben werden .
Öffentliche digitale
Infrastruktur fördern
Viele der genannten Initiativen und andere ehrenamtliche
Digitalprojekte die ihren Quellcode offenlegen, also Open Source
sind, und die teilweise als Freizeitbeschäftigung begannen, sind
inzwischen unersetzlich in digitalen, öffentlichen und
privatwirtschaftliche Anwendungen. In einer Statista Umfrage von
2024 gaben 69% der befragten Unternehmen an, dass sie Open Source
Software verwenden. Sie sind deswegen Teil einer digitalen
Infrastruktur, zu der auch Rechenkapazitäten, Übertragungstechnik
und Daten gehören.
Die Europäische Union sollte vermehrt darauf achten, dass
zentrale digitale Strukturen und Plattformen nicht von wenigen
kommerziellen Monopolen dominiert werden, die mit Suchmaschinen,
App Stores oder elektronischen Zahlungssystemen ihre Dienste
verkaufen. Investitionen in eine öffentliche digitale
Infrastruktur unterstützen den Zugang zu Freiem Wissen. Der
Zugang zu Mobilitätsdaten verschiedener Anbieter ermöglicht es
Menschen, die ehrenamtlich kostenlose Mobilitäsanwendungen
entwickeln, Fahrpläne für alle Verkehrsträger bereitzustellen. Die
EU sollte eine derartige öffentliche Infrastruktur unterstützen,
indem sie öffentlichen Einrichtungen die Arbeit mit offener
Software und offenen Daten vorschreibt – oder zumindest selbst
damit arbeitet und so auch selbst zu einem Teil der Community wird,
die sich an der Pflege und Weiterentwicklung beteiligt. Weiterhin
sollte sie Anreize zur Beteiligung zu setzen und Hindernisse wie
langsame Rechenkapazitäten zu vermeiden. Das Design solcher
Infrastrukturen in Open Source erlaubt transparente, dezentrale
Verwaltung und Aufsicht. Eine solche Transparenz unterstützt das
Vertrauen in Netze und Anwendungen und damit die Beteiligung auch
an Projekten des Freien Wissens.
Eine wichtige Maßnahme ist zudem, die Hürden für den Zugang zu
Daten und Information zu beseitigen. Konkret sollte beispielsweise
das öffentliche Interesse in der Richtlinie über audiovisuelle
Mediendienste (AVMD Richtlinie) stärker beachtet werden.
Millionen Europäer betrachten Inhalte online auf verschiedenen
mobilen Geräten. Je nach Herkunftsland können Inhalte gesehen oder
nicht gesehen oder abgerufen werden. Denn während die EU in
vielerlei Hinsicht einen digitalen Binnenmarkt hat, gibt es im
Bereich der audiovisuellen und urheberrechtlich geschützten Inhalte
Ausnahmen. Diese machen es oft unmöglich, Inhalte von
öffentlich-rechtlichen Sendern in anderen EU-Ländern anzusehen oder
zu teilen, auch für Wissensprojekte wie Wikipedia. Dieser
Flickenteppich schadet der Informationsfreiheit und dem Austausch
von Wissen auf europäischer Ebene. Das Geoblocking
öffentlich-rechtlicher Inhalte sollte daher innerhalb der EU so
weit wie möglich aufgehoben werden.
Digitales Ehrenamt ist ein
gesamt-europäisches Phänomen. Bei diesem Edit-a-thon in Warschau
tragen polnische Wikipedianer*innen zu mehr Wissen über das Thema
„Art + Feminism“ in der polnischsprachigen Wikipedia bei. Foto:
Laura Jerzak, Edyton Art+Feminism 15, CC BY-SA 4.0
Ehrenamtliche
Fördern
Digitale Gemeingüter und nichtkommerzielle Gemeinschaften werden
überwiegend von Ehrenamtlichen getragen. Diese Menschen widmen ihre
Zeit, Energie und Kreativität dem Ziel, Probleme zu lösen und
Leerstellen zu füllen, die sie sehen, und so effektiv die Welt
besser zu machen. Die Videokonferenzanwendung BigBlueButton etwa
entstand während Corona aus dem Wunsch, für Schulkinder eine
einfach nutzbare, aber gleichzeitig datensparsame Möglichkeit für
Unterricht zu Hause anzubieten.
Allerdings brauchen auch Ehrenamtliche ab einem gewissen Punkt
finanzielle Förderung, damit sie sich angemessen um die Pflege der
Software oder einen ausreichend großen Server kümmern können. Denn
genau so wie kommerzielle, lizenzpflichtige Software regelmäßige
Sicherheitsupdates braucht oder eine verbesserte
Nutzendenoberfläche, muss auch eine Open Source Software
kontinuierlich gepflegt und angepasst werden – auch, um im
Wettbewerb gegen gut designte proprietäre Lösungen bestehen zu
können.
Darüber hinaus sollten ehrenamtliche gemeinwohlorientierte
Communitys durch aktiven Austausch mit EU Ebenen gefördert werden.
Eine verbindliche Zivilgesellschaft-Quote in Beratungsgremien und
bei der Ausarbeitung von Gesetzesvorschlägen sollte eingeführt
und damit echte Mitgestaltung ermöglicht werden. Dabei braucht es
ausreichend lange Fristen für Konsultationen für
zivilgesellschaftliche Akteure, da diese in der Regel ihre
Expertise neben einer hauptberuflichen Beschäftigung einbringen.
Arbeitsaufwände etwa für Anhörungs- und Beratungsverfahren sollten
finanziell angemessen kompensiert werden. Kooperationen, aber auch
die finanzielle Unterstützung von Netzwerken und Initiativen etwa
durch Steuererleichterungen oder die Ermöglichung regulärer Treffen
durch finanzielle Unterstützung von Community-Konferenzen gehören
dazu.
Letztlich muss sich die EU konsequent für das Recht auf
Anonymität und Verschlüsselung einsetzen. Damit das Internet
ein Raum bleibt, in dem sich jede Person frei bewegen kann und
keine Angst haben muss, für die Mitarbeit an einem
Community-Projekt, eine Meinung oder Publikation bestraft zu
werden, fordern wir schon lange das Recht auf Anonymität und
Verschlüsselung. Gerade angesichts der menschenrechtsfeindlichen
Tendenzen überall in Europa erhalten diese Forderungen neues
Gewicht.
Eine neue Ära des freien
Wissens
Zugang zu Wissen ist eine zentrale Bedingung für einen
demokratische Diskurs, denn dieser lebt von informierten Menschen.
Öffentliche Büchereien, Museen oder Universitäten – die ihre
Bestände und Forschungsergebnisse zunehmend digitalisieren –
pflegen und bewahren Wissen. Wir brauchen aber auch freien Zugang
zu diesem Wissen – im Digitalen wie im Analogen. Davon profitieren
wir als Bürger und Bürgerinnen, aber auch Wissensprojekte wie die
Wikipedia. Damit freie Wissensprojekte, aber auch die
Bibliotheksnutzenden, Museumsbesuchende oder Forschenden in Europa,
Zugang zu mehr Wissen erhalten, fordern wir die EU auf, einen
Digital Knowledge Act zu erlassen.
Welche Hürden hindern traditionelle Institutionen des Wissens
daran, ihren öffentlichen Auftrag zu erfüllen und noch mehr
Menschen digital Zugang zu Bildung und Wissen zu gewähren?
Wissenschaftliche Forschung, die mit EU-Fördergeld aus den
Horizon Europe Programmen finanziert wurde, verschwindet hinter
Bezahlschranken, anstatt für alle und ohne Hürden zur Verfügung zu
stehen. Öffentliche Büchereien würden gerne ihre E-Bücher zu
denselben Bedingungen verleihen wie ihre gedruckten Materialien.
Aber Verlage stellen oft nur Teile Ihrer Neuerscheinungen als
E-Ausgaben zur Verfügung, nicht zur Veröffentlichungszeit oder
stellen andere Bedingungen der Restriktion.Wikipedianer*innen, die
Artikel auf einen neuen Wissensstand bringen wollen, können dadurch
nicht zeitnah auf alle verfügbaren Wissensquellen zugreifen.
Offizielle Werke, öffentlich in Auftrag gegebene Studien und
anonymisierte Gerichtsurteile müssen endlich öffentlich und digital
zugänglich werden: Derzeit sind diese Dokumente kaum oder gar nicht
zugänglich, obwohl sie mit öffentlichen Geldern finanziert
wurden.
Und auch Hürden, die sich aus Teilen des Urheberrechts oder des
Datenbankrechts ergeben, sollten die europäischen Gesetzgebenden
einreißen.
1⃣ Stand mit den 4⃣ Partnerorganisationen aus dem Bündnis F5⃣
und 1⃣2⃣ Meetups und Talks sowie 7⃣ Sessions im
Hauptprogramm und viele Gespräche mit den Menschen, die uns auf der
re:publica am Stand besucht oder zu unseren Sessions
gekommen sind. Das ist der kurze und knackige Rückblick auf
die re:publica vom 27. bis 29. Mai 2024. Danke für Ihre
Aufmerksamkeit! Ob es ausführlicher geht? Aber klar!
Der F5 Stand: Coole Menschen,
coole Sticker und viel Austausch
Einen Ort für den Austausch zu aktuellen digitalpolitischen
Themen mit einem klaren Fokus auf die Frage: Wie können wir
gemeinwohlorientiert ein sicheres, freies und offenes Internet für
alle gestalten? Das sollte der gemeinsame Stand mit Reporter ohne
Grenzen, der Open Knowledge Foundation Deutschland, AlgorithmWatch
und der Gesellschaft für Freiheitsrechte bei der re:publica 2024
bieten. Die vier Organisationen bilden mit uns das
zivilgesellschaftliche Digital-Bündnis F5. Dass der Plan
aufging, haben die vielen Besuche von und Diskussionen mit
digitalen Akteur*innen aus Politik und Zivilgesellschaft deutlich
gezeigt.
Foto: Ekvidi, Republica24-F5-Montag-90, CC
BY-SA 4.0
Zahlreiche
Digitalpolitiker*innen haben uns am Stand besucht, um sich zu den
Themen auszutauschen, die die Partnerorganisationen im Büdnis F5
bearbeiten: Von Freiheitsrechten im Netz über algorithmische
Diskriminierung bis hin zu offenen Daten und communitygetriebenen
Plattformen. Sabine Grützmacher, Bildungsinformatikerin und für die
Grünen im Bundestag, diskutiert hier mit Mitgliedern aus dem
Bündnis F5.
Foto: Ekvidi,
Republica24-F5-Dienstag-Stand-22, CC BY-SA 4.0
Ebenso gut
gelaunt wie seine Parteikollegin: Tobias Bacherle,
Bundestagsabgeordneter und Mitglied im Digitalausschuss des
Bundestages, zu Besuch am Stand.
Foto: Ekvidi,
Republica24-F5-Dienstag-Stand-8, CC BY-SA 4.0
Die
Digitalpolitikerin Anna Kassautzki (SPD), die sich für die
Förderung eines Open Source Ökosystems einsetzt, im Gespräch mit
Malte Spitz und Kai Dittmann von der Gesellschaft für
Freiheitsrechte.
Foto: Ekvidi,
Republica24-F5-Dienstag-Stand-1, CC BY-SA 4.0
Die
Bundesvorsitzende der SPD, Saskia Esken (2.v.r.), nimmt die
gemeinsamen Forderungen des Bündnis F5 für eine
gemeinwohlorientierte Digitalpolitik entgegen. Die Parteien und
Kandidaten, die sich dieses Jahr zur Wahl für Europa stellen, haben
die Publikation bereits vor der re:publica erhalten.
Foto: Ekvidi,
Republica24-F5-Montag-Stand-24, CC BY-SA 4.0
Ebenfalls
für einen Austausch vorbeigeschaut hat die ehemalige
Justizministerin und heutige Antisemitismusbeauftragte des Landes
Nordrhein-Westfalen, Sabine Leutheusser-Schnarrenberger (r.), hier
im Gespräch mit Franziska Heine, der Geschäftsführenden Vorstädin
von Wikimedia Deutschland, die außerdem …
Foto: Ekvidi,
Republica24-F5-Dienstag-Stand-37, CC BY-SA 4.0
… Steffi
Lemke, die Bundesministerin für Umwelt, Naturschutz, nukleare
Sicherheit und Verbraucherschutz am Stand willkommen heißen
konnte.
Foto: Ekvidi, Republica24-F5-Montag-78, CC
BY-SA 4.0
Ilja Braun
von Reporter ohne Grenzen mit der Juristin und
Menschenrechtsaktivistin Stella Assange. Die Frau von Julian
Assange kämpft seit Jahren für die Freilassung des
WikiLeaks-Gründers.
Die
ehemalige Digitalministerin Taiwans und Hackerin Audrey Tang (r.)
und Glen Weyl (Mitte), Ökonom und Forscher bei Microsoft Research,
haben gemeinsam das Buch „Plurality: The Future of Collaborative
Technology and Democracy“ geschrieben. Zu diesem Thema haben die
beiden mit Besucher*innen an unserem Stand diskutiert.
Foto: Ekvidi,
Republica24-F5-Dienstag-Stand-13, CC BY-SA 4.0
Alle
Partnerorganisationen des Bündnis F5 haben verschiedene
Publikationen mitgebracht, in denen sie über ihre Arbeit
informieren. – wie das Forderungspapier zur Förderung des digitalen
Ehrenamts von Wikimedia Deutschland. Außerdem gab es natürlich
Sticker, Jutebeutel und andere Kleinigkeiten am gemeinsamen
Stand.
Foto: Ekvidi,
Republica24-F5-Mittwoch-Stand-2, CC BY-SA 4.0 Foto: Ekvidi,
Republica24-F5-Mittwoch-Stand-2, CC BY-SA 4.0
Weil die
zahlreichen Sticker („Wikipedia, das erklärt einiges“ oder
„Knowledge ist human“) und Publikationen bei vielen Besucher*innen
auf Interesse stießen …
… mussten
wir am Stand immer wieder Publikationen nachfüllen…
Foto: Ekvidi,
Republica24-F5-Mittwoch-Stand-2, CC BY-SA 4.0
Besonders
beliebt war der Sticker mit der Aufschrift „Wikipedia – das erklärt
einiges“
Foto: Ekvidi,
Republica24-F5-Mittwoch-Stand-8, CC BY-SA 4.0
Worüber
Stefan Kaufmann (l.), Referent für Politik und öffentlicher Sektor,
und John Hendrik Weitzmann, ehemaliger Justiziar von Wikimedia
Deutschland, sich hier unterhalten, kann nur gemutmaßt werden.
Vermutlich irgendwas mit offenen Daten und freien Lizenzen. Denn
dazu konnte man Stefan bei einem Meetup am letzten Tag der
re:publica am Stand befragen.
Foto: Ekvidi, Republica24-F5-Montag-29, CC
BY-SA 4.0
Lillie Iliev
(mit Mikro), Leiterin des Teams Politik und öffentlicher Sektor,
und Friederike von Franqué, (links davon) Referentin für EU und
internationale Regelsetzung, sprachen am Stand darüber, warum die
Wikipedia wenig Probleme mit Desinformationen hat – anders als die
Plattformen der Tech Giganten.
Unsere Sessions: Von KI in der
Bildung bis Care-Work für Software
Zum ersten Mal seit 2019 fand die re:publica in diesem Jahr
wieder in der Station Berlin statt. Mit dem ehemaligen Postbahnhof
in Berlin-Kreuzberg sind besonders viele re:publica Erinnerungen
verbunden. Denn seit 2012 hatte das Festival dort
stattgefunden. Auf neun Bühnen, in vier Workshopräumen sowie
zwei Lightning-Boxen und im Atrium fand das Hauptprogramm statt.
Wikimedia Deutschland war mit sieben Sessions dabei. Alle unsere
Sessions im Überblick
finden Sie hier
Foto: Ekvidi, Republica24-F5-Montag-35, CC
BY-SA 4.0
Bei der
Session „Warum wir eine offene KI für die Bildung fordern“
lieferten sich die offene KI (links im Bild) und die geschlossene
KI (rechts im Bild) einen Schlagaubtausch – und bezogen das
Publikum in die Debatte mit ein. Gewonnen hat am Ende die offene
KI. Mit den zehn Handlungsempfehlungen zum Einsatz von KI in der
Bildung hat Wikimedia Deutschland eine Debatte zum Thema
angestoßen.
Foto: Ekvidi, Republica24-F5-Montag-62, CC
BY-SA 4.0
Um das
Förderprogramm re*shape ging es bei der Session „Opening up with
care: Wie marginalisiertes Wissen frei und sicher geöffnet werden
kann“ Riham Abed-Ali, die Projektmanagerin des Programms von
Wikimedia Deutschland, diskutierte mit Teilnehmenden des Programms:
Llanquiray Painemal (r.) ist eine chilenische
Menschenrechtsaktivistin in Deutschland und Christopher A. Nixon
(2. v.r.) ist Professor für Soziale Ungleichheit und Sozialpolitik
an der Hochschule RheinMain. Hajdi Barz wiederum ist
Gründungsmitglied des feministischen Romnja* Archiv, RomaniPhen
e.V.
Foto: Ekvidi, Republica24-F5-Dienstag-38,
CC BY-SA 4.0
Careless
whisper or voice of the future: Europäische Digitalpolitik: Unter
diesem Titel diskutierte unsere Geschäftsführende Vorständin
Franziska Heine (r.) mit dem Ex-Europaabgeordneter Felix Reda
(Mitte) und dem Europa-Abgeordneten Sergey Lagodinsky. (l.) Sie
spannten den Bogen von der digitalen Bubble bis nach Brüssel und
sprachen über die heißen Digitalthemen zur anstehenden
Europawahl.
Foto: Ekvidi, Republica24-F5-Dienstag-86,
CC BY-SA 4.0
Mit dem
Global Digital Compact will die UN Leitlinien für ein sicheres,
freies Internet festlegen. Weil Wikimedia Deutschland sich mit
zivilgesellschaftlichen Akteur*innen in den Prozess eingebracht
hat, haben wir auf der re:publica zur Diskussion gestellt „Who
cares about international digital policy? What do we expect from
the UN Global Digital Compact 2024“
Re:publica verpasst? Zahlreiche Sessions, so auch die Diskussion
über europäische Digitialpolitik mit Franziska Heine, wurden per
Video oder Audio aufgezeichnet. Zu finden sind sie hier.
Erstmals konnten Wählende den Digital-O-Mat zur Landtagswahl
2017 in Nordrhein-Westfalen nutzen. Die Menschen in Deutschlands
bevölkerungsreichstem Bundesland konnten damit Abweichungen und
Übereinstimmungen zwischen den eigenen Positionen und denen der
Parteien überprüfen. Im Gegensatz zum Wahl-O-Mat liegt der Fokus
auf Fragen rund um Digitales und Freies Wissen.
Jeder Digital-O-Mat ist
anders
Zu welchen Fragen Wählende im jeweiligen Digital-O-Mat die
Positionen der Parteien mit den eigenen abgleichen können, hängt
von mehreren Faktoren ab: Welche Aspekte rund um Freiheit und
Sicherheit im Digitalen, freien Zugang zu Wissen sowie digitale
Bildung oder Infrastruktur werden in der kommenden Legislatur
wahrscheinlich geregelt – oder sollten aus Sicht der am Wahl-O-Mat
beteiligten Organisationen geregelt werden? Und welche
Regelungskompetenzen und -bedarfe bestehen auf der Ebene von
Ländern, Bund und EU. Vor der Landtagswahl in Nordrhein-Westfalen
2017 haben wir die Parteipositionen zu acht Themen mit Digitalbezug
erhoben. Dazu gehörten unter anderem Bildung und offene
Lernmaterialien, Sicherheit und digitale Überwachung, freier
Internetzugang oder die offene, digitale Nutzung von Daten aus
Kommunal- und Landesverwaltungen. Auch 2018 zu den
Landtagswahlen in Hessen und Bayern und zur Bundestagswahl 2021 gab es
Digital-O-Maten.
Auch vor 2017 hat Wikimedia Deutschland Parteien vor Wahlen zu
ihren netzpolitischen Positionen und Vorhaben befragt.
2011 etwa haben wir alle Parteien, die zur Berliner
Abgeordnetenhauswahl angetreten sind, mit 30 Fragen rund um
offene Verwaltungsdaten, freie Lizenzen, Internetzugang und Open
Source Software konfrontiert. Die Antworten konnten Wählende
im Wiki nachlesen und so mit den eigenen Positionen abgleichen.
Vor der anstehenden Europawahl in diesem Jahr sind hingegen ganz
andere Themen relevant. Mit dem aktuellen Wahl-O-Mat kann man überprüfen, wie es mit
den Positionen der Parteien zu Themen wie KI-basierter
biometrischer Erfassung von Menschen im öffentlichen Raum,
Chatkontrolle, elektronische Identitäten und die Frage, ob Europol
künftig Daten mit Unternehmen und nicht-europäischen Drittstaaten
austauschen dürfen soll.
„Auf EU-Ebene werden die wichtigsten gesetzlichen
Weichenstellungen vorgenommen, die dann auf nationaler Ebene
umgesetzt werden. Gesetzgebung zu digitalen Themen aus Brüssel
betrifft ehrenamtliche Projekte wie die Wikipedia ebenso wie den
digitalen Alltag von uns allen. Denn auf EU-Ebene werden Gesetze
zur Plattformregulierung, zum Umgang mit Gesundheitsdaten oder zur
Nutzung sogenannter Künstlicher Intelligenz gemacht.“ Lilli
Iliev, Leiterin des Teams Politik und öffentlicher Sektor bei
Wikimedia Deutschland.
Vorgänger des Wahl-O-Mat: Die
Wahlprüfsteine
Foto: Wolf1949, Wahlprüfsteine des DGB
1987 , CC0 1.0
Auch vor 2017 hat Wikimedia Deutschland Parteien vor Wahlen zu
ihren netzpolitischen Positionen und Vorhaben befragt.
2011 etwa haben wir alle Parteien, die zur Berliner
Abgeordnetenhauswahl angetreten sind, mit 30 Fragen rund um
offene Verwaltungsdaten, freie Lizenzen, Internetzugang und Open
Source Software konfrontiert. Die Antworten konnten Wählende
im Wiki nachlesen und so mit den eigenen Positionen abgleichen.
Sogenannte Wahlprüfsteine haben in Deutschland eine lange Tradition.
Interessenverbände haben sie häufig vor Wahlen erstellt, um ihre
Mitglieder darüber zu informieren, wie Parteien sich zu Fragen
positionieren, die für sie besonders relevant sind. Der Deutsche
Geerkschaftsbund (DGB) hat die Wahlprüfsteine bereits in den 50er
Jahren eingeführt. Vom Bundesverband für Motorradfahrer über den
Deutschen Familien-Verband, den Bund der Steuerzahler bis hin zum
Lesben- und Schwulenverband gibt es zahlreiche Interessengruppe,
die dieses Instrument genutzt haben, um Wahlempfehlungen für die
Mitglieder oder Anhängerschaft zu erstellen.
So kommen die Positionen der
Parteien in den Digital-O-Mat
Nach der Auswahl der Themen ging es an die Recherche zu den
Positionen der Parteien. Dafür haben die Organisationen, die den
Digital-O-Mat gemeinsam entwickelt haben, zunächst bei den Parteien
nachgefragt. Und zwar bei denen, deren Einzug in das jeweilige
Parlament sicher oder sehr wahrscheinlich war. Wer zunächst nicht
geantwortet hat, wurde freundlich erinnert! Die Aussagen zu
verschiedenen Themen sollten die Parteien belegen: mit
Parteibeschlüssen, vergangenem Abstimmungsbehalten, Wahlprogrammen
oder Ähnlichem.
Blieben Antworten ganz aus und konnten wir auch keine Belege für
eindeutige Positionen finden, haben wir bei dem jeweiligen Thema
eine neutrale Haltung angenommen. Menschen, die den Digital-O-Mat
nutzen, können in der Auswertung dann detaillierte Informationen zu
den Parteipositionen finden. Der Digital-O-Mat spuckt also nicht
nur Ergebnisse aus, er legt auch offen, welche Inhalte dahinter
stehen.
Wer hat’s erfunden – und
warum?
Über die Jahre haben sich verschiedene Vereine aus der digitalen
Zivilgesellschaft als “Koalition Freies Wissen” daran beteiligt, zu
verschiedenen Wahlen Digital-O-Maten zu erstellen. Die
Ursprungsversion haben neben Wikimedia Deutschland sechs weitere
Vereine erarbeitet:
die Bewegung für freie Infrastrukturen und offene
Funkfrequenzen Freifunk,
Sie alle verbindet das Engagement für netzpolitische Themen. Sie
eint dabei, dass sie sich für die Durchsetzung von Freiheits- und
Bürgerrechten im digitalen Raum und für den freien Zugang zu
Wissen, Daten und Software einsetzen – mit unterschiedlichen
Schwerpunkten und Mitteln. Wir alle haben uns in unterschiedlicher
Form an dem Projekt Digital-O-Mat beteiligt: Mit Zeit, finanzieller
Unterstützung, Programmierexpertise und Code sowie mit Input dazu,
zu welchen digitalpolitischen Themen die Parteien jeweils nach
Positionen gefragt werden sollten – welche Themen aktuell sind und
welche uns als Internetnutzende besonders betreffen.
Bei der Auswahl der Themen für den Digital-O-Mat haben die sehr
unterschiedlichen Expertisen der Vereine und Bündnisse geholfen,
die an dem Projekt beteiligt waren und sind. Sie haben vor den
Landtags-, Bundestags-,und Europawahlen analysiert, in welchen
Politikfeldern und bei welchen anstehenden Gesetzesvorhaben ein
Digitalbezug da ist.
Die Software hat der Datenjournalist Sebastian Vollnhals entwickelt.
Sie steht auf GitHub unter freier Lizenz zur Verfügung. Zur
Europawahl 2024 hat sich die Ortsgruppe Braunschweig des Vereins
Digitalcourage den Code geschnappt, den Digital-O-Mat
wiederbelebt und mit Inhalten gefüttert. Der Digital-O-Mat ist
damit eins von vielen Digitalprojekten in Deutschland, in dem viel
ehrenamtliches Engagement steckt – und das gleichzeitig vielen
Menschen nützt.
Wir engagieren uns seit 20 Jahren für die vielen digitalen
Ehrenamtlichen, die in der Wikipedia Wissen frei zur Verfügung
stellen. Aber auch im politischen Bereich machen wir uns dafür
stark, dass sich die rechtlichen Rahmenbedingungen für alle
Freiwilligen im digitalen Raum verbessern. Eine unserer Forderungen
lautet zum Beispiel, dass die gemeinwohlorientierte Entwicklung von
Software, Apps oder Plattformen auch als gemeinnützig anerkannt
werden muss. Mehr zum digitalen Ehrenamt und unserem Engagement
dafür lesen Sie hier.
Mehr aus 20 Jahren Engagement
für ein besseres Internet
Mit Kaffeefiltern gegen
Upload-Filter
Heute vor
fünf Jahren war die deutschsprachige Wikipedia für einen Tag nicht
nutzbar. Wer in der Online-Enzyklopädie Wissen suchte, fand statt
der vertrauten Startseite einen schwarzen Bildschirm und einen
Text, der erklärte, warum das so ist. Was das ganze mit
Kaffeefiltern und unserer politischen Arbeit zu tun hat, berichten
wir heute. Wir werden in diesem Jahr 20. Daher erzählen wir an
besonderen Tagen Geschichten aus 20 Jahren Engagement für Freies
Wissen und ein besseres Internet.
Engagement für freie CC
Lizenzen: Terra X Videos in der Wikipedia
Das
Ehrenamtlichen-Projekt Wiki Loves Broadcast ist seit Jahren Dreh-
und Angelpunkt des Engagements für freie Lizenzierung im
öffentlich-rechtlichen Rundfunk. Ein Baustein ist die Kooperation
mit der Redaktion von Terra X (ZDF). Die Zusammenarbeit wurde bei
einem Workshop in Mainz noch einmal vertieft.
re*shape Programm: „Wir
wollen marginalisierte Perspektiven in Deutschland sichtbar
machen“
Mit dem
Programm re·shape fördert Wikimedia Deutschland zehn Projekte, die
dem Wissen von marginalisierten Communitys Raum und Sichtbarkeit
geben. Eines der Projekte ist Social Media und Freie Lizenzen von
KARAKAYA TALKS. Das Team von KARAKAYA TALKS untersucht gemeinsam
mit ihrer Mentorin aus der Wikipedia-Community, wie ihr Content in
der Wikipedia Verwendung finden kann.
Die rapide Verbreitung von Künstlicher Intelligenz, eine
wachsende Flut an Desinformation, zunehmend veränderte
Mediennutzung – unsere digitale Welt steht vor großen
Herausforderungen. So auch die Wikipedia. Trends wie diese
erfordern neue Strategien, um die Online-Enzyklopädie als
verlässliche Quelle für Freies Wissen auch für die kommenden
Generationen zu erhalten.
Gemeinsam mit Wikipedia-Autor*innen, Wikipedia-Interessierten,
Expert*innen, Partner*innen der Vereine Wikimedia Deutschland,
Österreich und der Schweiz findet daher vom 7. bis 9.
Juni der erste Wikipedia-Zukunftskongress statt. Er bietet
Raum für inspirierende Diskussionen, gemeinsames Brainstorming und
erste Ansätze, um die Zukunft der Wikipedia aktiv
mitzugestalten.
Den Eröffnungsvortrag am Freitag, 7. Juni, hält der deutsche
Informatiker und Silicon Valley-Visionär Richard Socher – ein Pionier in den Bereichen
Künstliche Intelligenz, Neuronale Netze und Deep Learning sowie CEO
und Gründer von you.com, dem ersten Chat-Suchassistenten.
Der Zukunftskongress ist mit drei Leitfragen überschrieben: Was
braucht die Welt von Wikipedia? Wie gestalten wir den
technologischen Wandel? Wie verändert sich die Community? Zu all
diesen Schwerpunkten gibt es am Samstag, 8. Juni, Vorträge und
Podiumsdiskussionen.
Chris Tedjasukmana, Professor
für Alltagsmedien und Digitale Kulturen an der Johannes
Gutenberg-Universität Mainz, geht unter dem Titel „Unordentliche
Wissenspraktiken – Wie verändert sich der Umgang mit Wissen?“ der
Frage nach, wie wir unser bestehendes Wissensverständnis durch neue
Wissensformen erweitern können.
Und was bedeutet das für die Wikipedia? Wie bleiben ihre Inhalte
relevant? Für wen sind sie überhaupt eine wichtige
Informationsquelle und für wen nicht (mehr)? Darüber diskutiert
Tedjasukmana im Anschluss mit Christian Pentzold (Universität
Leipzig & Center for Digital Participation), der langjährigen Wikipedianerin
CaroFraTyskland– und Sinthujan Varatharajah, freie*r
Wissenschaftler*in und Essayist*in.
Mit dem Wandel durch KI beschäftigt sich auch Theresa Züger, Leiterin der vom Bundesministerium für
Bildung und Forschung (BMBF) geförderten
Nachwuchsforscher*innengruppe Public Interest AI.
Nach ihrem Vortrag über Chancen für gemeinwohlorientierte
Initiativen, KI für sich zu nutzen, ist Züger auch Teilnehmerin des
Podiums „Handschrift, Buchdruck, WWW– und was kommt dann?“. In der
Diskussion mit Carina Zehetmaier (Präsidentin
der Vereinigung „Women in AI“), Hannah Monderkamp (Mitglied der
Chefredaktion von Heise Medien), Kurt Jansson (Wikipedianer und
Leiter der Dokumentation des Spiegel-Verlags) sowie Franziska Heine (Vorständin von Wikimedia
Deutschland) geht es um die Frage: Wie können wir im Zeitalter von
Smartphone, Social Media und KI dafür sorgen, dass die
Wikipedia-Idee nicht irgendwann so gestrig wirkt wie das gedruckte
Lexikon?
Alle wollen Communitys aufbauen: Plattformen, Creator*innen,
Marken. Welche Lebenszyklen durchlaufen Online-Communitys dabei?
Darüber spricht der Kulturwissenschaftler Daniel Sigge anhand seiner
Erfahrungen als Community-Manager bei reddit, TikTok, YouTube und
Google in seinem Vortrag.
Und wohin entwickelt sich die Wikipedia-Community in der
Zukunft? Seit ihrem Start im Jahr 2001 wurden in der
deutschsprachigen Wikipedia mehr als 4 Millionen Benutzer-Accounts
erstellt. Manche sind dabei geblieben, viele nicht. Ca. 6.000
Wikipedia-Aktive editieren regelmäßig. Einige Gruppen sind bis
heute in der Community unterrepräsentiert.
Darüber diskutieren auf dem Panel Daniel Sigge, Jan Krewer (Senior Policy Analyst bei Open Future)
DomenikaBo (langjährige
Wikipedianerin) und Martin Gerlach (Senior Research
Scientist bei der Wikimedia Foundation).
Teile Deine Vision!
Zur Frage, wie sich die Wikipedia weiterentwickeln soll, können
alle Interessierten auf der Programmseite des Zukunftskongresses
anonym ihre Meinung und Visionen teilen. Die eingegangen
Beiträge werden gesammelt und mit nach Nürnberg genommen.
Unter diesem Link geht es zur Anmeldung für die kostenlose
Online-Teilnahme am Wikipedia-Zukunftskongress:
Bezahltes Schreiben im PR-Auftrag in der Wikipedia, ist ein
Thema, das mich und die Wikipedia-Community seit einigen Jahren
umtreibt. Das Thema wabert seit etwa 2010 durch die Wikipedia, mal
intensiver und mal weniger intensiv diskutiert; mal mit Skandal und
mal ohne. Aber wenn man sich, ganz ohne Insiderkenntnisse, einfach
mal durch Wikipedia-Artikel lebender Personen clickt (sei es in der
deutschen Ausgabe oder der englischen): normalerweise riecht man
die gekauften und geschönten Artikel 500 Kilobyte gegen den Wind.
Die peinlichen PR-Artikel: weil auch die siebte Teilnahme am
Rettet-die-Bergdackel-Benefiz-Gala-Dinner getreulich unter dem
Punkt „gesellschaftliches Engagement“ gelistet wird. Die weniger
peinlichen PR-Artikel: weil sie so nichtssagend sind.
Wie lange das Problem existiert und wie sehr es schon vor vielen
Jahren auffiel, wurde mir letztens beim lesen gewahr. Es war ein
Fantasy-Crime Roman – komplett fiktiv, mit vagen Bezugspunkten zu
unserer Welt. Und selbst dort kommt Wikipedia-PR-Schreiben vor. Es
geht um „Moon over Soho“ von Ben Aaronovitch. Erstmal erschienen
2012 bringt es der Roman auf den Punkt:
Auf deutsch etwa:
„Die Reichen, vorausgesetzt sie vermeiden Prominenz, können
etwas Unternehmen um ihre Anonymität zu bewahren. Lady Tys
Wikipedia-Artikel las sich als wäre sie von einem PR-Schreiber
verfasst worden, denn zweifellos hatte Lady Ty einen PR-Schreiber
beschäftigt, um sicherzustellen, dass die Seite ihren Vorstellungen
entsprach. Oder wahrscheinlicher: Einer ihrer „Leute“ hatte eine
PR-Agentur beauftragt, die einen Freelancer beschäftigt hatte, der
das in einer halben Stunde runtergeschrieben hatte, damit er sich
schneller wieder auf den Roman konzentrieren konnte, den er grade
schrieb. Der Artikel gab preis, dass Lady Ty verheiratet war, zu
nicht weniger als einem Bauingenieur, dass sie zwei schöne Kinder
hatten von denen der Junge 18 Jahre alt war. Alt genug um Auto zu
fahren aber jung genug um noch zu Hause zu wohnen.“
Diese Beschreibung trifft auch zehn Jahre später auf einen
Großteil aller PR-Artikel zu. Schnell und lieblos, aber
professionell gemacht. Oft genug mit Versatzstücken aus anderen
Werbematerialien; zu unauffällig, um jemand ernstlich zu stören.
Aber auch zu nichtssagend, um der Leser*in auch nur den geringsten
Mehrwert zu bieten.
Damit hat ein Roman-Autor, der selber kein aktives Mitglied der
Wikipedia-Community ist, die PR-Problematik schon im Jahr 2012
richtiger eingeschätzt als ein relevanter Teil der diskutierenden
Community im Jahr 2022.
(Und Randbemerkung: die Community rächte sich, indem sie
Aaronovitchs Autoren-Artikel mit einem unvorteilhaften Autorenfoto
versah – no PR-flack weit und breit war hier unterwegs.)
Von einer anderen Form des beeinflussten Schreibens erfuhr ich
heute beim Mittagsessen. In immer mehr autoritären Regimes scheint
es vorzukommen, dass einzelne Wikipedia-Autor*innen, die in dem
jeweiligen Land leben, einen Anruf oder einen Besuch bekommen. Mit
dem freundlichen Tipp, doch den ein oder anderen Artikel zu
„verbessern“ sonst.. Das ist natürlich noch raffinierter: Einfach
einen etablierten Nutzer und dessen Vertrauensvorschuss nehmen und
in dieser Tarnung PR-Edits durchführen.
Menschen können auf der Wikipedia:Auskunft
Fragen an die Wikipedia richten. Die Fragen sind mal banal, mal
lehrreich, und manchmal hohe Poesie. Daran solltet ihr
teilhaben.
Ich stelle mich auf, Brust nach vorne, Kinn nach oben, räuspere
mich noch einmal und deklamiere:
Wir waren dieses Jahr mit WikiAhoi wieder bei der SMWCon dabei. Die
Konferenz zu Semantic MediaWiki findet zweimal pro Jahr statt, im
Frühling in Nordamerika und im Herbst in Europa. Letztes Jahr waren
wir schon in Wien dabei und dieses Jahr gings ins
herbstlich-sonnige Barcelona. In freundlicher, persönlicher
Atmosphäre wurden technische Neuigkeiten, innovative Projekte und
besondere Anwendungsfälle besprochen. Wir möchten Sie an den
wichtigsten Neuerungen teilhaben lassen.
Neuigkeiten aus der Semantic MediaWiki-Welt
Semantic
Forms (Version 3.4 September 2015) hat sich
mittlerweile als eigenständige Erweiterung etabliert und ist nun
technisch nicht mehr von der Grunderweiterung Semantic MediaWiki
abhängig. Weitere wichtige Änderungen:
Statt den Spezialattributen werden nun ParserFunctions
eingesetzt.
Kartenbasierte Eingabeformate (Google Maps, Open Layers) sind
nun möglich – diese werden nur eingesetzt, wenn Semantic Maps nicht
vorhanden ist.
Weiters wird nun Cargo unterstützt, es
lassen sich in Formularen auch Eingabeformate und die
Autovervollständigungsfunktion aus Cargo nutzen.
Dazu kann man nun auch „mapping“-Werte hinterlegen, das sind
andere Werte, als auf der Seite angezeigt werden.
Ein neuer Parameter erlaubt es, nur einzigartige Werte
speichern zu lassen.
Alle roten Links können nun mit einer einzelnen Einstellung auf
eine Formularauswahlliste weitergeleitet werden.
Die MediaWiki Stakeholder’s
Group nahm die Konferenz zum Anlass, um weitere
Schritte zu besprechen: Ziel der Gruppe ist die Koordination und
die Kommunikation mit Wiki-Nutzern in Unternehmen, die
Unterstützung von Entwicklern und Administratoren und die
offizielle Kommunikation mit der Wikimedia Foundation. Wikipedia hat etwas
andere Ziele als einzelne Drittnutzer der Software MediaWiki. Es
geht also stark darum, die Interessen der Nutzer von Wiki in
Unternehmen zu vertreten und in der Weiterentwicklung der
Software voranzutreiben.
Interessante neue
semantischeErweiterungen
gibt es zu Breadcrumbs, Zitaten, Sprachenlinks und
Metatags:
Semantic Breadcrumb
Links – mittels Attributen können Breadcrumbs erstellt
werden, die eine Hierarchie erzeugen, ohne Unterseiten erstellen zu
müssen.
Semantic Cite – unabhängig
von der Cite
Erweiterung, ermöglicht das seitenübergreifende Verwenden von
Zitaten und eine automatische/manuelle Quellenliste.
Semantic
Interlanguage Links – automatische Sprachanzeigen (gibt es
diese Seite in anderen Sprachen?) in Wikis mit Interwikis.
Und warum „eine Konferenz mit Folgen“? Diese Konferenz hat
Folgen auf mehreren Ebenen: Wir haben persönliche Kontakte für
Zusammenarbeit und Austausch geknüpft, es wurden Ideen
beflügelt und Inspirationen für neue Projekte ausgetauscht,
die Motivation wieder gestärkt, das Projekt MediaWiki als Ganzes
voranzubringen und nicht zuletzt viele Features und
Software-Änderungen besprochen, die in der Regel meist recht
schnell umgesetzt werden. Die Konferenz war somit ein voller
Erfolg.
Die Konferenz fand von 28.–30.10.2015 in Barcelona statt, in der
schönen Fabra
i Coats Kunstfabrik im Stadtteil Sant Andreu. Knappe 40
Teilnehmer nahmen an einem Tutorial- und zwei Konferenztagen
teil.
Die deutschsprachige Wikipedia-Community versucht wieder einmal,
die Regeln zum bezahlten Schreiben zu verschärfen. Das Thema wabert
ungelöst seit Jahren durch das Wikiversum. Und auch dieses
Meinungsbild ist ein notwendiger Schritt voran. Aber der Weg ist
noch weit. Der beste Kommentar meinerseits wäre die Komposition
eines Quartetts für Singende Säge, Bassdrum, Cembalo und
Spottdrossel.
Aber ich kann nicht komponieren. Deshalb kommt das Nächstbeste:
ein Gedicht.
Wikipredia
Die Regeln existieren und doch
nicht nach Mondstand
Die Ethik absolut seit
Anbeginn nein denn ja
Die Praxis gesperrt verworfen
gelöscht freigeschaltet
Wikipredia Darwinismus der
Agenturen Überleben des
Dreistesten
Darmstädter Madonna
Hans Holbein der Jüngere, 1526/1528
Öl auf Nadelholz (?), 146,5 × 102 cm
Sammlung Würth, Johanniterhalle (Schwäbisch Hall)
Wikipedia-KNORKEerwähnte ich ja an
dieser Stelle schon einmal. Berliner Wikipedianerinnen und
Wikipedianer treffen sich und erkunden zusammen eine ihnen
unbekannte Gegend. Soweit so üblich. Diesmal jedoch gab es etwas
besonderes: Auf ins Museum!
In Berlin gastiert gerade die Darmstädter
Madonna, ein 1526 entstandenes Gemälde von Hans Holbeim dem
Jüngeren. Diese Madonna hat eine bewegte Lebens- und
Reisegeschichte, ist eines der bedeutendsten deutschen Gemälde des
16. Jahrhunderts und kann Menschen auch über Jahre faszinieren.
Wunderbar, wenn man eine kundige Bilderklärung der Autorin des
exzellenten Wikipedia-Artikels dazu bekommt.
Wir trafen uns einige Minuten vor der Öffnung in kleiner Gruppe vor
dem Bode-Museum und konnten - da alle Anwesenden über eine
Jahreskarte verfügten - auch sofort zur Madonna und zur
Sonderausstellung "Holbein
in Berlin" begeben. Der Raum war noch leer, die
Museumswachmannschaft ließ freundlicherweise die leise aber
engagiert redende Gruppe gewähren. Ein einziger Saal, in dessen
Mittelpunkt die Madonna hängt. Links davon einige
Holbein-Teppiche, ansonsten weitere Bilder und Zeichnungen von
Holbein, Inspiratoren und andere Madonnen. Nicht überladen,
sinnvoll aufbereitet und mit einem klaren Konzept - eine der
besseren Kunstausstellungen.
Und dann ging es los: Es begann mit Schilderungen von der bewegten
Entstehungszeit zur Zeit des Basler Bildersturms im Auftrag des
Basler Ex-Bürgermeisters Jakob Meyer zum Hasen. Die Aussage des
Bildes traditioneller Marienfrömmigkeit in Zeiten der Reformation
war Thema, ebenso natürlich wie der Teppich und seine Falte. Wir
staunten über die Eigentümlichkeit, dass sich niemand auf dem
Gemälde eigentlich anschaut und wurden über dden Unterschied
zwischen Schutzmantelmadonnen und Stifterbildern aufgeklärt.
Vermutungen tauchten auf, wo das Bild wohl im Original hing -
vermutlich in der Martinskirche
als Epitaph - und wir verfolgten gedanklich seine Wanderung aus
Basel über den Grünen Salon im Berliner Stadtschloss bis hin zum
Hause Hessen und das Frankfurter Städelmuseum bis hin zum
spektakulären Verkauf an die Privatsammlung Würth. Die Meinungen
über die Sammlung Würth in der Gruppe waren durchaus geteilt,
ebenso wie die richtige Benennung des Bildes: ist es nun eher die
Darmstädter Madonna oder eher die Madonna des
Bürgermeisters Jakob Meyer zum Hasen?
Über die Darmstädter Madonna ging es dann zur Dresdner Madonna und
einem der prägenden Momente deutscher Kunstgeschichte: dem Dresdner
Holbeinstreit. Im 19. Jahrhundert wurde es den Menschen
bewusst, dass es zwei fast identische Holbein-Madonnas gab und nur
eine die echte sein konnte. In einer großen Ausstellung, unter
lebhafter Anteilnahme der Öffentlichkeit und erregten Debatten der
Experten entschieden sich die Kunsthistoriker schließlich für das
Darmstädter Gemälde. Eine Sensation, da die Kunstkennerschaft
vorher felsenhaft von der Originalität des Dresdner Gemäldes
ausging. Hier zeigte sich erstmals das Bemühen, um eine rein
sachlich, objektive Abwägung der verschiedenen Gesichtspunkte - der
Dresdner Holbeinstreit ist einer der Ausgangspunkte um die
Kunstwissenschaft als Wissenschaft zu etablieren. Und - wie sich
später herausstellte - lag die Kunstwissenschaft auch in diesem
ihren Anfangsurteil richtig; sämtliche mittlerweile vorhandenen
naturwissenschaften Verfahren die Darmstädter Madonna als die
originale der beiden bestätigten.
Erkenntnisse am Rande: eine weitere Kopie des Gemäldes
(beziehungsweise eine Kopie der Kopie - es stellt aus
unerfindlichen Gründen das Dresdner Exemplar dar) hat sich in das
Set des James-Bond-Filmes "Man lebt nur zweimal verirrt".
Hans Holbein der Jüngere:
Bildnis des Danziger Hansekaufmanns Georg Gisze in London, 1532.
Eichenholz, 96,3 × 85,7 cm. Gemäldegalerie Dahlem der Staatlichen
Museen zu Berlin – Preussischer Kulturbesitz
Und nachdem wir dann auch noch gerätselt hatten, wer die beiden
Knaben unterhalb der Madonna sind, den verschwundenen Haaren der
Tochter nachspürten und weiter über den Teppich in der
Renaissancemalerei sinniert hatten, kamen wir dann nach knapp einer
Stunde noch zu Georg Giesze. Giesze (auch Georg Giese) ist
Titelheld in einem anderen Holein-Hauptwerk, das praktischerweise
fünf Meter weiter links hing. Wieder mit Teppich und nun auch noch
mit Glas, Metall, Bücherregalen und Briefen. Gedanklich begleitete
wir Holbein dann weiter von Basel nach Antwerpen und London.
Mittlerweile hatte sich der Raum etwas gefüllt. Nachdem wir dann
noch den Weg aus dem Museum gefunden hatte (wie immer im Bodemuseum
nicht ganz einfach und jedes mal findet man zwischendurch neue
Säle) folgte noch ein erschöpfter Abschlusskaffee.
Eine Stunde fast allein mit der Madonna. Und immer noch Neues zu
entdecken.
Über den Dächern, Türmen und Gasometern Westberlins senkte sich
die Abendsonne. Ich stand auf den Zinnen des Ullstein Castles und
sinnierte. Direkt unter mir Straßentreiben, Sirenen, betrunkene
Jugendliche, ein Ausflugsboot auf dem Teltowkanal, radelnde
Ausflügler überquerten die Stubenrauchbrücke.
In der Ferne betrachtete ich die Türme des
Spitzenlastheizkraftwerks Lichterfelde, der Sendeturm auf der
Marienhöhe, den BfA-Büroturm und den ehemaligen Wasserturm im
Naturpark Schöneberger Südgelände. Heute Nacht auf dem Heinweg:
Welchen Weg sollte ich wählen? Unten, im Süden, über den Prellerweg
vorbei am Sommerbad am Insulaner? Die Nordvariante über den
Tempelhofer Damm und durch die Kopfsteinpflaster Tempelhofs? Oder
die Mittelweg, mit Erklimmen der Höhe am Attilaplatz und später
über den Ikea-Parkplatz? So viel zu wählen.
Wahlen spukten in meinem Kopf herum. Da war die
Mitgliedsversammlung unseres Dauergartenvereins. Die
Vorstandswahlen dort sollten wahrscheinlich, hoffentlich,
unspektakulär verloren. Aber die Anträge. Wenn ein einzelnes
Mitglied auf einem A4-Blatt 40 verschiedene Anträge stellt, richtig
ernsthaft, dann verspricht das Unterhaltung.
Die Bundestagswahl: Auf dem Weg zum Ullstein Castle passierte
ich zahlreiche Bundestagstagswahlplakate: den unlesbaren Blob der
Grünen in Tarnfarbenoliv, die bildhaft dargestellte Biederkeit der
Berliner SPD, zahlreiche Kleinparteien von Team Tödenhöfer über
Volt bis zur Tierschutzpartei. Und so sehr es mich schmerzte das zu
sagen: Das Plakatgame gewannen bisher die CDU und ihr
Wahlkreiskandidat Jan-Marco Luczak. Sowohl optisch – als auch
damit, überhaupt inhaltliche Aussagen fern von Plattitüden zu
machen.
Vor allem aber war ich innerlich bei einer ganz anderen Wahl.
Die Wikimedia Foundation wählte und wählt ihr Board, auf Deutsch
das ehrenamtliche Präsidium der Wikimedia Stiftung. Die Wikipedia
steht meinem Herzen näher als der Bundestag und selbst als der
Dauergartenverein. Aber die Board-Wahlen erfordern merh Gedanken.
Diese Gedanken bedurften des Kontextes.
Was ist die Wikimedia Foundation?
Die Wikimedia
Foundation (WMF) ist die Betreiberin der Wikimedia-Projekte wie
zum Beispiel der Wikipedia aber auch Wikimedia Commons und
Wikidata. Die Foundation hostet die Server, stellt die Technik,
ist am Ende rechtlich dafür verantwortlich was in den Wikipedien
passiert. Dafür hat die Foundation derzeit etwa 450 Angestellte,
ein Endowment von 90
Millionen Dollar und hatte 2020 Jahreseinnahmen von 127 Millionen
US-Dollar.
Wo genau die Grenzen zwischen dem Einfluss der Wikimedia
Foundation und den Communities liegen, ist umstritten. Letztlich
kann die Foundation alles ändern und machen in den Projekten. Sie
ist meistens weise genug, es nicht zu tun. Insbesondere schreiben
keine Foundation-Mitarbeiter*innen in ihrer Arbeitszeit Artikel
oder legen Inhalte in den Projekten an.
Die Foundation ist eine Organisation eigener selbstgenügsamer
Vollkommenheit. Sie hat keine Mitglieder und ist – rechtlich –
niemand rechenschaftspflichtig. Das Board besetzt sich prinzipiell
aus sich selbst heraus. Es hat entschieden die Hälfte der Sitze
Wahlen der weltweiten Wikip/media-Communities besetzen zu lassen zu
lassen.
Das Board of Trustees ist das
ehrenamtliche Aufsichtsgremium der Foundation. Es hat derzeit 16
Sitze. Davon steht einer Jimmy Wales als Gründer zu, sieben Sitze
besetzt das Board selber, acht Sitze werden durch eine weltweite
Communitywahl bestimmt.
Nun ist allein aus den Worten „ehrenamtlich“ und „weltweit / 450
Mitarbeiter / 127 Millionen Dollar Einnahmen“ klar, dass das Board
eine abstrakte Leitungsposition einnimmt. Alleine, einen Überblick
über so eine Organisation zu behalten, ist eine Mammutaufgabe.
Dieser Organisation noch Vorgaben zu machen und sie in eine
bestimmte Richtung zu lenken, eine Herausforderung.
Die Gefahr, in Detailinformationen zu ertrinken oder sich
hoffnungslos im Alltagsgeschäft zu verfangen, ist groß. Seiner
Aufgabe nach, beaufsichtigt das Board, was die Vollzeitkräfte
machen und besetzt die Geschäftsführung.
Was zur Zeit ein besonderer Job ist: Die Geschäftsführerin der
Foundation Catherine Maher verschwand im April 2021 überraschend.
Der Posten ist seitdem unbesetzt. Ebenso wie sich die Chief
Operations Officer im Jahr 2021 verabschiedete, die Abteilungen
Communication und Technology auch niemand im Vorstand haben. Auf
dem Schiff besetzt nur eine Notbesatzung an Offizier*innen die
Brücke. Dem Board obliegt es derzeit, dieses Führungsvakuum schnell
und kompetent zu beenden.
Grundsätzlich sollte jede*r Kandidat*in zwei Kriterien
erfüllen. Sie sollte meine inhaltlichen Ziele teilen. Und sie
sollte in der Lage sein, sich in einem ehrenamtlichen Job gegen
eine komplette Organisation aus Vollzeitangestellten zu behaupten.
Oft genug stehen bei solch ehrenamtlichen Gremien Kandidat*nnen zur
Wahl, bei denen ich denke „Will Schlechtes, aber wird das
erreichen“ und „Will Gutes, ist aber planlos. Am Ende werden die
Hauptberuflichen machen was sie wollen. Oder es gibt Chaos.“
Angesichts der bewegten Zeiten, in denen wir leben; angesichts
der latenten Führungslosigkeit der Foundation derzeit, möchte ich
Kandidat*innen, die sich durchsetzen können. Kandidat*innen, die
nach Möglichkeit die US-Zentrik der Foundation aufbrechen können.
Ich möchte Kandidat*innen, die verstehen, dass Wikip/media keine
allgemeine Weltbeglückungsorganisation ist, sondern sehr
spezifische Sachen sehr gut durchführt – und andere überhaupt nicht
kann. Es bringt nichts, sich auf allgemeine Weltbeglückungsziele zu
stürzen, die weder die Foundation noch die Communities umsetzen
können.
Insgesamt stehen 19 Kandidat*innen zur Auswahl, die um vier
Plätze streiten. Dabei sind Wikimedia-Urgesteine ebenso wie
Newbies, viele Männer, mir auffallend viele Inder, viele
Kandidat*innen mit NGO-Hintergrund, kaum eine*r, der/die
fortgeschrittene IT-Kenntnisse hat.
Die Urgesteine
Dariusz
Jemielniak – Professor of Management,
daueraktiv auf allen Ebenen und vielleicht der einzige Mensch, der
intellektuell versteht wie Wikipedia funktioniert.
Rosie
Stephenson-Goodknight – WikiWomensGroup, Women
in red, you name it. Bei überraschend vielen der
Wikipmedia-Genderaktivitäten, die funktionieren, ist Rosie
Stephenson-Goodknight beteiligt.
Gerard Meijssen – gefühlt
war Gerard schon Wikipedianer bevor es Wikipedia gab. Vielleicht
der spannendste Autor des Meta-Wikiversums und ein Chaot.
Mike Peel – langjähriges
Mitglied des Funds Dissemantion Committees. (FDC) Hat bei mir in
der Rolle durchgehend einen schlechten Eindruck hinterlassen.
Ravishankar Ayyakkannu – Mr.
Tamil Wikipedia, der seinem Resumee zufolge seit 2005 in der
Community und mit externen Partnern (wie Wikipedia Zero, Google)
zusammenarbeitete. Gewinnt bei mir Diversitätspunkte, weil er nicht
nur aus dem Global South stammt, sondern auch Ausbildung und
Berufstätigkeit dort durchführte.
Lorenzo Losa –
Ex-Vorsitzender von Wikimedia Italia.
Farah Jack Mustaklem – Software Engineer,
einer der wenigen Kandidaten mit Ahnung von Software. Aktiv bei den
Wikimedians of the Levant und der Arabic language User Group. Mir
persönlich zu sehr USA-sozialisiert für eine Board-Mitgliedschaft,
andererseits sicher in jeder Hinsicht kompetent.
Douglas Ian Scott –
Präsident von Wikimedia South Africa, Organisator der Wikimania
2018 und einziger Kandidat, den ich dank eines langen Wartepause am
Kofferband irgendeines Wikimania-Flughafens persönlich besser
kennenlernte – und begeistert war.
Iván Martínez – langjährig
engagiert bei Wikimedia Mexiko, LGBTQ+-Aktivist und soweit ich
hörte, das Wikiversum Lateinamerika ist begeistert von ihm.
Pavan Santhosh Surampudi –
Community Manager at Quora. Versteht also vermutlich professionell
etwas von Communities.
Adam Wight – Programmierer,
Ex-Angestellter und WMF und WMDE und neben Gerard der Vertreter des
Ur-basisdemokratischen, selbstorganisierten und
Gegen-Informationsmonopole-Geistes des frühen Movements.
Vinicius Siqueira – in Wiki
Movimento Brasil
Newbies
Es kann sich hierbei um langjährige und erfahrene
Wikipedianer*innen handeln, die im kleinen Rahmen auch Projekte
oder Gruppen organisiert haben. Erfahrungen in oder mit größeren
Organisationen im Wikiversum fehlt vollkommen.
Lionel Scheepmans
Pascale Camus-Walter
Raavi Mohanty
Victoria Doronina
Eliane Dominique Yao
Ashwin Baindur
Wen werde ich wählen?
Leute, die sich durchsetzen können, und die auch die Grenzen des
Wikiversums sinnvoll einschätzen können. Perspektiven auf das
Leben, anders aussehen als „in US-NGOs sozialisiert“ werden
bevorzugt.
Die Top 4
Douglas Ian Scott
Iván Martínez
Adam Wight
Dariusz Jemielniak
Top 8
Rosie Stephenson-Goodknight
Lorenzo Losa
Farah Jack Mustaklem
Gerard Meijssen
Wählbar
Reda Kerbouche
Pavan Santhosh Surampudi
Ravishankar Ayyakkannu
Wer wird wählen
Es wählen alle Menschen, die vage aktive Accounts in einem
Wikimedia-Projekt haben. Die Bedingungen dafür sind niedrig
angesetzt. Für Autor*innen ist es nötig 300 Bearbeitungen zu haben,
kein Bot zu sein und höchstens in einem Projekt gesperrt zu sein.
Die Bedingungen für die Board-Wahlen sind somit einfacher zu
erfüllen als die Bedingungen zum Sichten in der deutschen
Wikipedia. Die Kriterien mussten am 5. Juli 2021 erfüllt sein. Es
hilft nicht, jetzt noch schnell zu editieren.
Das Wahlsystem
Es gilt das Präferenzwahlsystem.
Dieses wird weltweit von einschlägigen Fachleuten als besonders
fair bezeichnet. Es verzerrt den Wählerwillen weniger als viele
andere Wahlsysteme. Praktisch wird es allerdings nur selten
eingesetzt. Die bekannteste Wahl mit Präferenzwahl in letzter Zeit
war die Bürgermeister*in-Wahl in New York, New York.
Bei Wahlsystem nummeriert man „seine“ Kandidat*nnen nach
Präferenzen. Die beste Kandidatin bekommt eine Eins, der Kandidat
danach eine zwei und so weiter. Hält man keine Kandidatin mehr für
geeignet, hört man auf zu nummerieren.
Bei der Wahl werden in der ersten Runde alle Präferenzen mit „1“
gezählt. Ein Kandidat hat am wenigsten davon. Dieser scheidet aus.
Von allen „1“-Wählerinnen des Kandidaten werden nun die
„2“-Präferenzen seiner Wählerinnen auf die entsprechenden
weiteren Kandidaten verteilt. Und so weiter, bis nur noch so viele
Kandidatinnen übrig sind, wie es Plätze zu besetzen gilt.
Im ICE ist Deutschland. Der Zug fährt ein und hält. Das Schild am
Gleis behauptet tapfer „Zugdurchfahrt“. Die Türen lassen sich
öffnen. Am Zug steht nichts geschrieben, außer Wagennummern, die
nicht zu den Reservierungen passen. Das Publikum bleibt irritiert.
Etwa die Hälfte der Anwesenden geht in den Zug und bleibt im
Wageninnern ratlos stehen. Die andere Hälfte steht ratlos am
Bahnsteig.
Schließlich: Lichter gehen an. Der Zug verkündet mittels seiner
Anzeigen nun auch, nach Kassel zu fahren. Eine Frau
entschuldigt sich über die Lautsprecheranlage über die falschen
Wagennummern, man solle ich immer zehn wegdenken „Also 22 statt der
angezeigten 32.“
Ein Mensch mit re:publica-Bändchen am Arm verscheucht die ältere
Dame ohne Reservierung von seinem Platz und liest den gedruckten
Spiegel. Ich höre ein angeregtes Gespräch zwischen einem
Musicaldarsteller und einer Abteilungsleiterin im Innenministerium,
die sich gerade kennenlernen über, den relativen Wert von
Musikgymnasien in Berlin. Geht es noch deutscher?
Illustration aus
dem Buch ""Le tour du monde en quatre-vingts jours" Alphonse de
Neuville & Léon Benett
Passenderweise habe ich ein entsprechendes Buch mitgenommen. Nils
Minkmars „Mit dem Kopf durch die Welt.“ Das hat schon auf dem Cover
ein ICE-Fenster und geht der Frage nach, was Deutschland bewegt.
Minkmar lässt sich über deutsche Normalität aus. Der deutsche
Ingenieur, lange Jahrzehnte Sinnbild der Normalität, sei nicht mehr
normal. Minkmar erzählt aus seiner französisch-deutschen
Kindheit:
„Meine Mutter nannte dann immer eine
Berufsgruppe, die uns besonders fern war, nämlich les
ingenieurs. Wir waren in Deutschland […] und das ganze frisch
aufgebaute Land ruhte auf Säulen, die les ingenieurs
berechnet, gegossen und zum Schluss noch festgedübelt hatten. […]
Viele Jahre später sollte ich die Gelegenheit haben, diese seltene
Spezies besser studieren zu können. Sie saßen direkt hinter mir,
zwei ausgewachsene Exemplare: Ingenieure, Familienväter, auf der
Rückfahrt von einer Dienstreise. Sie plauderten über die sich
verändernden Zeiten. […] Fernsehen, Marken, Politiker, auf keinem
Gebiet fanden sich diese beiden braven Männer wieder, alles zu
grell und bunt, zu aufgeregt. Ihre spezifischen Werte und Tugenden,
Sorgfalt und diese stille Freude an der eigenen Biederkeit, das
alles war an den Rand gerückt. Ingenieure waren nun Exzentriker.
[…] Diese Männer fanden sich kulturell kaum zurecht.“
Wenn „der deutsche Ingenieur“ nicht mehr normal in Deutschland ist,
sind es jetzt Ministerialbeamtinnen und Musicaldarsteller?
Forschung Maschinenbau Braunschweig
Minkmar war noch nicht in Braunschweig. Oder Braunschweig ist nicht
normal. Da steige ich harmlos aus dem Zug und die Stadt schlägt mir
„Deutscher Ingenieur“ rechts und links um die Ohren. Braunschweig
hebt das Thema "autogerechte Stadt" in Höhen, die selbst mir als
gebürtigem Hannoveraner unerreichbar schienen.
Braunschweig.
Bahnhofsvorplatz.
VW ist daran beteiligt, ist klar in der Gegend. Aber nicht nur. Ich
wandelte also Freitagabend gegen 21 Uhr auf der Suche nach einem
Wegbier durch das verlassene Braunschweig, passierte die Stadthalle
und wurde prompt begrüßt mit „Tag des Maschinenbaus. Herzlich
Willkommen.“
Vor allem aber fiel mir bei diesem Wandeln auf, wie
unglaublich gepflegt diese Stadt aussieht. Ich erblickte
keine einzige Kippe auf dem Weg. Selbst die Großbaustelle, über die
irrte, wirkte irgendwie aufgeräumt. Viel verwunderlicher war, dass
selbst die in Braunschweig reichlich vorhandenen 1970er-Großbauten
gepflegt und sorgsam hergerichtet wirkten. Die Stadthalle selber,
offensichtlicher spät 1960er/früh 1970er-Stil wirkte besser
gepflegt als Berliner Gebäude nach zwei Jahren. Die Wege und Lampen
darum herum: offensichtlich keine zehn Jahre alt. Sie wirkten wie
frisch aus der Packung genommen.
Wegbier. In
Braunschweig nur schwerlich aufzutreiben, dann aber
stilgerecht,
Selbst die Schwimmbäder sind alle gepflegt(*), alle haben
gleichzeitig geöffnet und keines ist aus obskuren Gründen gesperrt.
Da spielt nicht nur bürgerschaftliches Engagement eine Rolle,
sondern offensichtlich ist auch Geld vorhanden.
Auf dem Hotelzimmer, noch so ein sehr gut gepflegter und
hergerichteter Bau, der einem „1970er!“ ästhetisch schon ins
Gesicht schreit, mit dem Hotel-Wlan (7 Tage, 7 Geräte) nachlesend,
wie das nun ist mit Braunschweig. Bekanntes taucht beim Nachlesen
auf: Die physikalische-technische Bundesanstalt mit der Atomuhr;
geahntes lese ich (Volkswagen – hey, das ist Niedersachsen und die
Technische Universität existiert ja auch) und nicht bekanntes:
„Im gesamten Europäischen Wirtschaftsraum
(EWR) verfügt die Region Braunschweig über die höchste
Wissenschaftlerdichte,[103] im bundesweiten Vergleich über eine
hohe Ingenieurquote[104] sowie über die höchste Intensität auf dem
Gebiet der Ausgaben für Forschung und Entwicklung. In der Region
Braunschweig arbeiten und forschen mehr als 16.000 Menschen aus
über 80 Ländern[105] in 27 Forschungseinrichtungen sowie 20.000
Beschäftigte in 250 Unternehmen der
Hochtechnologie[106]“
Dazu noch „Braunschweig ist die Stadt mit der niedrigsten
Verschuldung Deutschlands.“ Und nach einer obskuren EU-Rangliste
ist Braunschweig die innovationsfreudigste Region der EU vor
Westschweden und Stuttgart. Hier lebt der deutsche Ingenieur. Hier
lebt die deutsche Technik. Was für ein passender Ort für Jules
Verne.
Jules Verne
Jules Verne; französischer Erfolgsautor des 19. Jahrhunderts und
vor allem bekannt als "Vater der Science Fiction." Von seinem
vielfältigen Werk sind vor allem die Abenteuer-Techno-Knaller wie
Zwanzigtausend Meilen unter dem Meer, die Reise Von der
Erde zum Mond oder die Reise zum Mittelpunkt der Erde
bekannt. Wikipedia und die Deutsche Jules-Verne-Gesellschaft hatten
ein gemeinsames Wochenende organisiert mit einer Tagung zu Jules
Verne und Gesprächen zu Wikipedia.
Volker Dehs
bestreitet das halbe Programm
Jules Verne, mir vor allem bekannt durch vage Erinnerungen an den
1954er Nemo-Film, Weiß-orange Taschenbücher und einen blau
eingebunden Robur-Roman, der mich verstörte, weil er so anders war
als die großen mir bekannten Abenteuerromane von Jules Verne. Warum
ich überhaupt fuhr: Intuition. Ich hätte nur schwerlich begründen
können, was genau mich reizte, aber die Mischung aus Vertrauen in
die Veranstalter, Science Fiction und Neugier auf diese andere
niedersächsische Stadt nach Hannover, trieben mich dorthin.
Verne selber gilt als Begründer Science Fiction. Und so bringt er
als Autor frankophile Literaten und Groschenromanfans, Ingenieure
und Naturwissenschaftler zusammen. Besessene Bibliographen waren
Thema und Anwesend, ebenso wie die phantastische Bibliothek in
Wetzlar – die Mischung der Jules-Verne-Aktiven unterscheidet sich
gar nicht so sehr von der Mischung der Wikipedia-Aktiven. Die
Perspektiven, aus denen Verne hier unter die Lupe genommen wurden,
waren vielgestaltiger als sie es in der Literatur sonst sind.
Faszinierend hier war die Neigung unterschiedlicher und leicht
besessener Menschen sich zu einem Thema auseinanderzusetzen.
Haus der
Braunschweigischen Stiftungen - Veranstaltungsort.
Dementsprechend hatte der Veranstalter, der Wikipedia-Autor
Brunswyk das Programm gestaltet: ist Verne eher katholisch oder
eher laizistisch? Kam der Wille zur Aufklärung in seinen Büchern
durch seinen Verleger Pierre-Jules Hetzel hinein, während auf Verne
eher zurückgeht, dass alles menschliche Streben gegenüber der
göttlichen Macht sinnlos bleibt? Wen inspirierte er? Ist es eine
sinnvolle Frage, dem nachzugehen, welche seiner Voraussagen, sich
bewahrheiten? Dazu kamen dann noch Exkursionen zu Friedrich
Gerstäcker, Fenimore Cooper, die Ingenieure, die ihre U-Boote dann
nach Jules Verne „Nautilus“ nannten – und stark von diesem
beeinflusst waren
Für mich brachte das Treffen interessante Erkenntnisse, wie die
Tatsache, dass Verne immer Theaterautor oder – produzent werden
wollte und wie sehr der Katholizismus sein Denken beeinflusste.
Romancier war er eher gezwungenermaßen – und verdiente mit seinen
zwei erfolgreichen Theaterstücken in seinem Leben ein Viertel so
viel Geld wie mit etwa 80 bis 100 Romanen.
Interessant das Rätseln aller Anwesenden, warum Vernes Roman "der
Grüne Strahl" so ein kommerzieller Erfolg war, was niemand der
Anwesenden nachvollziehen konnte. Und dann eine Dreiviertelstunde
später kam die Bemerkung in einem anderen Zusammenhang,
dass "der Grüne Strahl" quasi Vernes einziges Buch mit einer
weiblichen Hauptfigur war. Ich ahne einen Zusammenhang,Update: Es kam wie es kommen musst. Da denke ich mal, ich
habe etwas entdeckt, dabei habe ich nur etwas falsch verstanden.
Tatsächlich ist Der Grüne Strahl nicht das einzige Werk mit einer
Protagonistin. Das prägnanteste Buch ist dabei Mistress Branican*, da hier die Titelfigur
die komplette Handlung quasi im Alleingang bestreitet. Aber auch in
anderen Büchern spielen Frauen eine wichtige Rolle (und dieser
Umstand war Jules Verne sogar so wichtig, dass er in Interviews
darauf hinwies): Die Kinder des Kapitän Grant*, Nord gegen Süd*, Reise um die Erde in 80 Tagen*, Ein Lotterielos* ... und einige mehr.
(*Affiliate Links)
Für mich neu war die Erkenntnis, dass ein Großteil von Vernes Werk
gar nicht in den Bereich Science Fiction gehört, sondern es
(fiktive) Reisebeschreibungen sind. Und selbst dort wo Verne
Maschinen und phantastische Gerätschaften erfindet, dienen diese
vor allem dem Zweck zu reisen.
Und jetzt recherchiere ich, natürlich, zum Grünen Strahl.
Die Phantastische Bibliothek
Meine beiden Programmhighlights beschäftigten sich nur mittelbar
mit Jules Verne. Sie kamen von der Phantastischen Bibliothek
Wetzlar: zum einen der Rückblick von Thomas Le Blanc auf Wolfgang
Thadewald. Den großen Phantastik- und Jules-Verne-Sammler.
Thadewald verstarb 2014. Er
lebte in Langenhagen. Mehrere der Anwesenden hatten ihn noch
persönlich gekannt. Und die Schilderung seiner Sammlertätigkeit,
seiner Liebe zu Büchern und zu Menschen, aber auch die Besessenheit
mit der Thadewald an ein Thema heranging und auch von Krankheit
schon schwer gekennzeichnet das Arbeiten an Bibliographien nicht
lassen konnte – es ließ sich nicht anders beschreiben als bewegend.
Sicher war dieser Vortrag mein emotionaler Vortrag des
Programms.
Wer auch immer aber auf die Idee kam, den Vortrag von Klaudia
Seibel zu Future Life: Wie (nicht nur) Jules Verne dabei
hilft, die Zukunft zu gestalten an Ende der Konferenz zu legen:
Chapeau! Das Projekt ist, kurz gesagt, ein Projekt der
Phantastischen Bibliothek. Die stellt zu bestimmten Themen Dossiers
zusammen, wie Science-Fiction-Autoren sie sich vorstellen. Die
Berichte werden manchmal von öffentlichen Stellen, öfter von
Großunternehmen bestellt, die damit selber zukunftsfähig werden
wollen und in die Zukunft denken.
Wobei Auftraggeber von Staats wegen selten sind. Die meisten
Aufträge kommen aus der Privatwirtschaft. Die allerdings meist
gleich umfangreiche Verschwiegenheitsklauseln verlangt, weshalb die
Phantastische Bibliothek da wenig zu sagen kann.
Da haben also Autoren und Mitarbeiter der Bibliothek ein profundes
Wissen über die Science-Fiction-Literatur und die größte Bibliothek
ihrer Art im Hintergrund und seit mittlerweile einigen Jahren eine
große Datenbank aufgebaut, was Autoren zu verschiedenen Themen
schreiben.
Als jemand, der ich selbst weiß, wie viele Situationen ich durch
gelesene Bücher interpretiere – Bilder aus diesen Büchern im
Hinterkopf habe und mir immer wieder mal sagen muss, dass ein Roman
nur bedingt real ist, glaube ich sofort, dass es nichts gibt, was
so sehr Denkprozesse auslösen und Kreativität triggern kann, wie
Romane. Der befreit das Hirn gerade vom strikt
logisch-folgerichtigen Denken, verrückt die Perspektive etwas nach
links oder oben, und schon öffnen sich vollkommen neue
Gedankenwege. Die Idee ist so brillant, dass es überraschend ist,
dass sie wirklich angenommen wird. Anscheinend wird sie das.
Mensch Maschine Normal
Und nachdem ich dann wieder im Zug saß und das erste Handy-Ticket
meines Lebens gekauft hatte, fragte ich mich wieder. Ist diese
Stadt – die mir in vieler Hinsicht – so unfassbar „normal“
vorkommt, vielleicht die große Ausnahme? Sind die
Musicaldarsteller, die mit „dem Alex“ [Alexander Klaws]
telefonieren, normal? Die Menschen im Ministerium? Die größten
Jules-Verne-Experten des Landes, die alle noch einen anderen
Brotjob haben? Oder eher die Normalität vieler Menschen, die darin
besteht, am Ende des Monats zu überlegen, wie denn die letzten 10
Tage mit dem leeren Konto noch überbrückt werden können?
Brauschweig ist die verstädterte Mensch-Maschine-Kopplung. In
seiner Normalität sicher schon wieder ein Ausnahmefall in
Deutschland. Aber ich sah die Zukunft: sie sitzt in einer
Bibliothek in Wetzlar und liest Science-Fiction-Romane.
Auch zu Schwimmbädern ein schönes Minkmar-Zitat aus dem
Mit-dem-Kopf-durch-die-Welt.Buch:
„Nichts gegen das große Geld und die
wenigen, die es genießen können, aber die Stärke mitteleuropäischer
Gesellschaften liegt gerade in der Mischung. Für Reiche ist es in
Singapur, Russland und Malaysia ideal. […]Glaspaläste und Shopping
Malls gibt es auf der ganzen Welt, bald vermutlich auch unter
Wasser und auf dem Mond. Öffentliche Freibäder, Stadtteilfeste oder
Fußgängerzonen, in denen sich Reiche und Arme, Helle und Dunkle,
Christen und Muslime mit ihren Kindern vergnügen und drängeln, gibt
es nur hier. Ich fand es immer erstaunlich, dass es in Algerien
beispielsweise keine öffentlichen Schwimmbäder gibt oder dass man
in den USA oder in Brasilien Mitglied in einem Club werden muss.
Das ist eine teure und in vieler Hinsicht sozial sehr
voraussetzungsreiche Angelegenheit, nur um mit den Kindern mal
schwimmen zu gehen, es sei denn natürlich, jeder hat seinen eigenen
Pool im Garten, was, für mich zumindest, wie eine Definition von
struktureller Langeweile klingt.“ (s. 104)
*Dieser Post enthält Affiliate Links zu geniallokal. Es
handelt sich dabei um Werbung. Ich bekomme eine kleine Provision,
wenn ihr dort bestellt, und ihr habt bei den Guten
bestellt.
I still remember the time when real life meetings for
Wikipedians were new and adventurous and a bit scary. Did one
really want to meet these strange other people from the Internet?
How would they be? Could they even talk in real life or would they
just sit behind a laptop screen staring on it for hours?
My first meeting in Hamburg – THE first Wikipedia meeting in
Hamburg - would consist of three people (Hi Anneke, Hi Baldhur!)
sitting in a pub, and just waiting and seeing what would happen.
These meetings were kind of improvised, in a pub, quite private and
personal in nature and no talk about projects, collaborations, “the
movement” whatever. Just Wikipedia and Wikipedians having a nice
evening.
So what a fitting setting to celebrate this day in Berlin just the
old school way. Half improvised, organized by our dearest local
troll user:Schlesinger
on a talk page, we met in a pub, it was not clear who would come
and what would happen except some people having a good time.
And so It was. In the “Matzbach” in the heart of Berlin-Kreuzberg
seven people promised to come, in the end we were almost twenty.
Long time Wikipedians, long-time-no-see-Wikipedians, a Wikipedian
active mostly in Polish and Afrikaans, some newbies and two and a
half people from Wikimedia Deutschland. Veronica from Wikimedia
Deutschland brought a tiny but wonderful home-baked cake, and we
just talked and laughed, talked about history and future.
Actually, mostly we talked about future.
About the Wikipedian above 30, who has just started a new a
university degree in archaeology, the question whether the Berlin
community should have its own independent space, industrial beer,
craft beer and the differences, the district of Berlin-Wedding, the
temporary David-Bowie-memorial in Berlin-Schöneberg, the vending
machine for fishing bait in Wedding, new pub meet-ups in the
future, who should come to the open editing events, how to work
better with libraries, colorful Wikipedians who weren’t there,
looking for a new flat, whether perfectionism is helpful or rather
not when planning something for Wikipedians, explaining Wikipedia
to the newbie, the difficulties of cake-cutting and whatsoever.
No frustration, almost no talk about meta and politics, just
Wikipedians interested in the world, Wikipedia and eager to be
active in and for Wikipedia and with big plans for the future. Old
school. So good.
Crossposting eines Posts von mir aus demWikipedia
Kurier. Erfahrungsgemäß lesen das dort und hier ja doch andere
Menschen.
Wikipedistas kommen und gehen. Manchmal gehen mehr, manchmal
weniger. Einzelne davon fallen durch ihr Wirken in der gesamten
Wikipedia auf oder versuchen sich wenigstens durch einen
spektakulären Abgang in Szene zu setzen. Die meisten Autoren und
Autorinnen aber gehen genauso still und leise wie sie gekommen sind
und gearbeitet haben.
Die unseligen Autorenschwund-Debatten der unseligen Wikimedias
kümmern sich ja um Zahlen und nicht um Autorinnen und Autoren. Wie
armselig! Den Meta-aktiven Communitymitgliedern - aka Wikifanten -
fallen vor allem die anderen Wikifanten auf, die entschwanden.
Dabei zeigt sich bei genauerer Betrachtung, dass es um lauter
einzelne Individuen mit verschiedenen Vorlieben, Arbeitsstilen und
Interessen geht, die in Wikipedia tätig waren und sind. Es gibt vor
allem diejenigen, die kommen, einen Beitrag leisten und dann wieder
verschwinden. Der größte Teil der tatsächlichen Wikipedia wird von
Menschen und Accounts gestaltet, deren Edits fast nur im
Artikelnamensraum aufzufinden sind. Manchmal arbeiten sie
unermütlich über viele Jahre, manchmal auch nur einige Wochen an
einen oder zwei Artikeln. Viele davon sind als IP aktiv, so dass
sich fast nichts über sie sagen lässt. Vielleicht sind die
Beitragenden per IP auch gar nicht viele, sondern eine einzige sehr
fleißige Autorin? Wer weiß?
Viele Wikipedianerinnen und
Wikipedianer sind derzeit inaktiv.
Anlässlich des Projektes
WikiWedding und in meinem Bestreben möglichst viele
Wedding-Aktive daran zu beteiligen, lese ich ja derzeit viele
Artikel zu einem Themengebiet, das mir in den letzten Jahren eher
fremd war und an dessen Entstehung ich nicht beteiligt war. Wer
sich in den letzten Monaten am Thema beteiligt hat, ist mir
bewusst, wer sich von 2001 bis 2014 des Weddings angenommen hat,
musste ich nachlesen. Eine spannende Lektüre voller mir unbekannter
Namen und Accounts. Neben einigen mir bekannten Wikipedistas waren
dort vor allem mir unbekannte Accounts. Accounts, die oft aufgehört
haben zu editieren. Meist sind sie still und leise gegangen. Ihre
Edits und Kommentare geben keinen Hinweis warum. Aber anscheinend
war es anderswo schöner. Oder sie hatten den Einruck, alles in
Wikipedia geschrieben zu haben, was sie beitragen wollten. Um
diesen Autorinnen und Autoren zumindest nachträglich etwas
Aufmerksamkeit zu geben, um ihre Namen kurz aus den Tiefen der
Versionsgeschichten zu retten, sollen hier einfach einige
Autorinnen(?) und Autoren gewürdigt werden, die sich um den Wedding
in Wikpedia bemühten bevor sie verschwanden.
Da ist zum Beispiel der Artikel zur Chausseestraße.
Ein Mammutwerk von Gtelloke,
dessen Wikipedia-Edits sich von Juni bis Dezember 2012 fast
ausschließlich auf diesen Artikel beschränkten.
Bild: Die Chausseestraße 114-118 in Richtung
Invalidenstraße von Gtelloke
Da ist der Artikel zum Wedding selber.
Angelegt 2002 von Otto, dessen
letzter Edit aus dem Dezember 2004 stammt. Im November 2004 dann
maßgeblich ausgebaut von Nauck, der sich
auch sonst dem Ortsteil und seinen Themen widmete. Artikel zu
Moabit, den Meyerschen Höfen, Mietskasernen und Schlafgängern waren
Teil seines kurzen Werks, das im Wesentlichen nur zwei Wochen im
November 2004 dauerte, aber die Grundlagen wichtiger Artikel zur
Berliner Sozialgeschichte legte. Ein Blick auf seine Benutzerseite
zeigt auch den Geist der Wikipedia-Frühzeit: ''GNU rockt! Der König
ist tod, lang lebe das Volk! Lang lebe die Anarchie des Netzes!
Licht und Liebe''
Weiterer Ausbau erfolgte durch 87.123.84.64,
auch zu wikipedianischen Urzeiten. Dann passierte 500 Edits und
acht Jahre im Wesentlichen nichts – mal ein Halbsatz hier, mal die
Hinzufügung von drei Bahnstrecken dort, Hinzufügen und Löschen von
berühmten Persönlichkeiten bis im Dezember 2014 der erste heute
noch aktive Wikipedianer hinzukommt: Fridolin
freudenfett verpasst dem Artikel mit „Katastrophalen Artikel
etwas verbessert)“ eine Generalüberholung.
Der Leopoldplatz;
angelegt von Frerix, der in
den immerhin fünf Jahren seiner Wikipedia-Aktivität nie auch nur
eine Benutzerseite für nötig hielt und anscheinend auch in keine
Diskussion verwickelt wurde. Zu seinen wenigen Beiträgen
gehören neben der Anlage des Leopoldplatzes auch noch die Anlage
der englischen Stadt Sandhurst, die Anlage des Kreuzviertels in
Münster und des Three Horses Biers. Dann war er/sie wieder weg.
Mutter des Artikels ist hier aber 44Pinguine,
die den heutigen Inhalt maßgeblich prägt und auch heute noch aktiv
ist.
Nichts war für die Entwicklung des Weddings wohl so entscheidend
wie die Geschichte der AEG. Dieser Artikel stammte
in seiner Frühzeit von WHell,
engagiertem Wikifanten, mit ausführlicher
Artikelliste und Diskussionsseite, der uns 2007 verließ. Der
letzte Eintrag auf seiner Diskussionsseite war „Hallo WHell, ich
möchte Dich als den Hauptautor darüber informieren, dass ich den
Artikel John Bull (Lokomotive) in die Wiederwahl zum Exzellenten
Artikel gestellt habe,“ Größere Beiträge zur WEG folgten in den
späteren Jahren durch Peterobst –
aktiv von Februar bis April 2006 vor allem mit Beiträgen zur
Berliner Industriegeschichte, nach seiner Benutzerseite AEG-Kenner
und in Arbeit an einem Buch über den Konzern. Es folgten
80.226.238.197, von Georg
Slickers 2006 (auch heute noch aktiv, wenn auch recht
unregelmäßig), Flibbertigibbet
2006 ,
79.201.110.89 im Jahr 2008 und der unermüdlichen 44Pinguine.
Weiter ausgebaut von Onkel
Dittmeyer, aktiv von 2009 bis Juli 2015 in Technikthemen und
vielleicht immer noch unter neuem Account? Begann seine Karrier mit
der Nutzerseite „Hier ist Nichts und das soll so bleiben !“ und
hielt sich im Wesentlichen daran.
Da ist der Volkspark
Rehberge. Angelegt von Ramiro 2005,
aktiv 2005/2006, vor allem zum Thema Fußball. Maßgeblich ausgebaut,
umfassend überarbeitet 2007 von
84.190.89.208 und noch einmal 2010 stark erweitert von Katonka.
Landschaftsplaner mit unregelmäßigen Edits zwischen 2009 und 2014,
die Edits waren wenige, aber die Qualität war hoch.
Bild: LSG-6 Volkspark Rehberge Berlin
Mitte - Panoramabild auf die Wiesen des Volkspark Rehberge in
Berlin, Wedding (Mitte). Von:
Patrick Franke Lizenz: CC-BY-SA
3.0
Neben diesen Verschwundenen tauchen glücklicherweise aber auch
heute noch aktive Wikifanten auf. Immer wieder 44Pinguine und
Fridolin freudenfett. Darüber hinaus Definitiv,
Magadan,
Flibbertigibbet und Jo.Fruechtnicht.
Die Artikel entstanden durch Wikifanten und IPs. Accounts mit nur
einem Thema oder anderen, die über Jahre thematisch sprangen.
Während in der Frühzeit aber viele verschiedene Accounts und IPs an
den Artikel beteiligt waren, waren in den letzten Jahren deutlich
weniger Menschen aktiv. Fast alle inhaltlichen Edits in den von mir
angesehenen Artikeln verteilen sich auf 44Pinguine, Fridolin
freudenfett und Definitiv. Wikipedia wird kleiner und noch lebt
sie. Aber wir können all‘ den Verschwundenen danken, die vor uns
kamen.
Seit nun schon ein paar Jahren hört man immer wieder über
Probleme in der kroatischen (und zu einem gewissen Grad auch der
serbischen) Wikipedia. Rechte Gruppen sollen das Projekt übernommen
haben und alle Wikipedianer, die nicht ihrer Meinung sind,
rausgeekelt oder einfach gesperrt haben.
Lange war nichts passiert, aber seit Ende letzten Jahres sah
sich die WMF dann doch mal die Situation an und es wurde schon
zumindest ein Admin gebannt.
Nun hat die WMF ein Abschlußdokument veröffentlicht; oder
genauer schon Mitte Juni und ich habe es erst heute bei reddit
gesehen. In dem Dokument finden sich solche Perlen, als das in hrwp
behauptet wurde, Nazi-Deutschland habe Polen überfallen weil Polen
einen Genozid an Deutschen verübt hätten.
Der ganze Bericht kann
hier gefunden werden. Mich macht die ganze Geschichte sowohl
traurig als auch wütend. Wikipedia soll die Leute so gut es geht
aufklären und nicht Propaganda verbreiten!
Ich habe heute dieses Blog auf einen neuen Server umgezogen,
sein DNS aktualisiert und sein SSL repariert. Werde versuchen, es
nun wieder öfters zu befüllen. Wünscht mir Glück 🙂.
Bereits seit gestern und noch bis zum 28. April laufen die
Oversighter-Wahlen. Doc Taxon, User:He3nry
und Nolispanmo treten zur Wiederwahl an. Ich wünsche: Viel
Erfolg!
Eine der schöneren unbekannten Ecken der Wikipedia ist die Seite
zur
Auskunft. Dort können Menschen mögliche und unmögliche Fragen
stellen, die dann mal launisch, mal larmoyant, mal ernsthaft oder
auch gar nicht beantwortet werden. Wie im wahren Leben und eine
ewige Fundgrube obskuren Wissens, seltsamer Fragestellungen und
logischen Extremsports.
Nicht die DDR. Bild: Giorgio Conrad
(1827-1889) - Mangiatori di maccheroni. Numero di catalogo:
102.
Dort nun fragte vor ein paar Tagen ein unangemeldeter Nutzer:
"Warum
gab es in der DDR eigentlich nur Makkaroni (die in Wirklichkeit
Maccheroncini waren), aber keine Spaghetti? Das erscheint mir nach
Lektüre einiger Bücher aus der DDR so gewesen zu sein und ist mir
auch so von meiner aus Ex-DDR-Bürgern bestehenden Verwandtschaft
bestätigt worden. Warum?"
Es folgte eine längere und mäandernde ausgiebige Diskussion, die
immerhin folgendes ergab:
* Anscheinend gab es in der DDR Spaghetti, zumindest erinnerten
sich einige der Diskutanten an derartige Kindheitserlebnisse.
* Ob Spaghetti so verbreitet waren wie Makkaroni oder Spirelli,
darüber bestand Uneinigkeit.
* Die Nudelsaucensituation war in Berlin besser als im Rest der
DDR.
* Die DDR allgemein pflegte in vielerlei Hinsicht traditionellere
Essgewohnheiten als Westdeutschland, die Küche der DDR ähnelte in
vielem mehr der deutschen Vorkriegsküche als dies für die
westdeutsche Küche gilt.
* In Vorkriegszeiten waren Makkaroni verbreiteter als
Spaghetti.
* Schon bei Erich Kästner wurden Makkaroni gegessen
* Der Makkaroni-Spaghetti turn im (west-)deutschen Sprachraum war
Mitte der 1960er
* Schuld könnten wahlweise das mangelnde Basilikum, die mangelnde
Tomatensauce, überhaupt mangelnde Kräuter, Italienreisen,
Gastarbeiter, Miracoli oder auch was ganz anderes sein.
* Klarer Konsens im Rahme: Sahne gehört keineswegs in Sauce
Carbonara!
Gab es in der DDR nicht: Miracoli. Bild:
Miracoli-Nudeln mit Mirácoli-Soße von Kraft. Von: Brian
Ammon, Lizenz: CC-BY-SA
3.0
Daneben tauchten eine ganze Menge Kindheitserinnerungen auf an
exotische Spaghettimahlzeiten mit kleingeschnittenen Spaghetti,
Ketchup-basierter Tomatensauce und anderen kulinarischen Exotika
des geteilten Deutschlands.
Einige Antworten, viel mehr Fragen:
* seit wann wird in Deutschland überhaupt Pasta gegessen?
* wie lange schon ist Tomatensauce verbreitet?
* seit wann essen westdeutsche Spaghetti?
* Und wer ist Schuld? Die Gastarbeiter? Die Italienurlauber?
Miracoli?
* Und wie kommen eigentlich die Löcher in die Makkaroni?
Also verließen wir dann erst einmal die Auskunft und die dortige
Diskussion und betrieben etwas weitere Recherche. Das heimische
"Kochbuch der Haushaltungs- und Kochschule des Badischen
Frauenvereins", veröffentlicht 1913 in Karlsruhe, kennt sowohl
Makkaroni wie auch Spaghetti. Ungewohnt für heute: die Makkaroni
werden in "halbfingerlange Stückchen gebrochen" und dann 25 bis 30
Minuten gekocht.
Neben den diversen Makkaroni-Gerichten gibt es auch einmal
Spaghetti. Die Priorität ist klar. Spaghetti werden erklärt als
"Spaghetti ist eine Art feine Makkaronisorte. Beim Einkauf achte
man darauf, daß sie nicht hohl sind"
Die "Basler Kochschule. Eine leichtfaßliche Anleitung zur
bürgerlichen und feineren Kochkunst" von 1908 kennt keine
Spaghetti aber diverse Gericht mit "Maccaronis". Darunter sogar
schon die Variante "a la napolitaine" mit Tomatensauce.
Weitere Recherche. Weitere Erkenntnisse bringt das Buch "Meine
Suche nach der besten Pasta der Welt: Eine Abenteuerreise durch
Italien", das die Ankunft der Makkaroni in Deutschland auf das
frühe 18. Jahrhundert verlegt. Die 1701 nachweisbaren "Macronen"
waren wohl eher Lasagne, aber Anfang des 18. Jahrhunderts
entstanden in Prag und Wien echte Makkaroni-Fabriken.
Die Pasta folgte anscheinend den jungen Männern der Grand Tour aus
Italien in das restliche Europa. Bestimmt waren die Grand Tours für
junge Männer, die mal etwas von der Welt sehen und klassische
europäische Bildung mitbekommen sollten, die auf der Tour aber
anscheinend nicht nur Statuen und Kirchen kennenlernten, sondern
auch Pasta.
Der Macaroni. Der Hipster seiner Zeit. Bild:
Philip Dawe: The Macaroni. A Real Character at the Late Masquerade,
1773.
In England gab es sogar einen eigenen Modestil Macaroni
für exaltierte junge Männer - "a fashionable fellow who dressed
and even spoke in an outlandishly affected and epicene
manner". Die englische Wikipedia schreibt dazu lakonisch:
"Siehe auch: Hipster. Metrosexuell." Komplett falsch wäre wohl auch
die Assoziation zur Toskana-Fraktion nicht.
Nach diesen extravagant und auffallend auftretenden jungen Männern
ist nun wiederum im Englischen der Macaroni
penguin - auf deutsch der Goldschopfpinguin - benannt.
Makkaroni-Penguin. Benannt nach dem Stil,
nicht nach den Nudeln. Bild: Macaroni Penguin at Cooper Bay, South
Georgia von Liam Quinn,
Lizenz: CC-BY-SA
2.0
Wie aber kommen nun die Löcher in die Makkaroni? Und seit wann?
Licht in dieses Dunkel bringt die "Encyclopedia
of Pasta." Diese lokalisiert die Entstehung der maschinellen
Pastafertigung - die für Makkaroni in zumutbarer Menge
unvermeidlich ist - in die Bucht von Neapel in das 16. Jahrhundert.
Dort existerte eine Heimindustrie mit Mühlen, an die sich relativ
problemlos eine im 16. Jahrhundert aufkommende ’ngegno da
maccarun anschließen lies, die es den Neapolitanern ersparte
stundenlang im Teig herumzulaufen, um ihn zu kneten: im
Wesentlichen Holzpressen mit einem Einsatz aus Kupfer, je nach Form
des Einsatzes entstehen verschiedene Nudelsorten und damit unter
anderem Makkaroni. Die Makkaroni wurden dann in langen Fäden zum
trocknen in die süditalienische Sonne gehängt.
Neapel, 19. Jahrhundert. Bild:
Giorgio Sommer (1834-1914), "Torre Annunziata-Napoli - Fabbrica di
maccheroni". Fotografia colorita a mano. Numero di catalogo:
6204.
Das hat alles nicht mehr wirklich etwas mit Spaghetti und der DDR
zu tun, beantwortet nicht, warum die Deutschen in den 1960ern
plötzlich lieber Spaghetti als Makkaroni mochten, oder warum die
Makkaroni bei ihrem ersten Zug über die Alpen die Tomatensauce in
der Schweiz ließen? Warum gibt es in Deutschland kein Äquivalent zu
"Macaroni and cheese" (mehr)? Gab es ein Miracoli-Äquivalent in der
DDR, bei dem es Pasta, Sauce und Käse schon in einer Packung gab?
Warum sind Makkaroni in Deutschland tendenziell lang und dünn in
vielen anderen Ländern aber dicker und hörnchenförmig-gebogen? Es
ist hochspannend. Und ein Grund, noch viel mehr zu
recherchieren.
Seit 2019 wählt das Wikiversum die coolsten Tools, die besten
Hilfsmittel, um in Wikipedia und anderen Wikis zu werken. Eines
davon ist der Pywikibot, der Bot aller Bots.
Schneeregen fegte waagerecht über Vorplatz des Tempelhofer
Hafens. Mein Pullover war gar nicht so kuschlig und dicht wie ich
ihn in Erinnerung hatte. Die Handschuhe waren im Laufe der Jahre so
fadenscheinig geworden, dass eine einzelne kurze Radtour die Finger
vereisen ließ.
Ein einsamer, von Weihnachten übrig gebliebener,
Quarkkeulchen-Stand vor dem Tempelhofer Hafen. Seine Lichter
verhießen Wärme. Der Weg dorthin: Von Entbehrungen gezeichnet. Der
Wind, der einem aus allen Richtungen ins Gesicht blies, trieb die
Leute davon. Sie wussten nicht wohin, denn alles war geschlossen
und zu Hause wollten sie ihre Mitbewohner nicht mehr sehen. Über
der Szene kreiste ein hungriger Taubenschwarm.
„Ist es nicht herrlich“, fragte ich DJ Hüpfburg. „So viel Platz!
Fast das ganze Hafengelände gehört uns. Und wir können uns
problemlos aus drei Meter Sicherheitsabstand anschreien.“ – Sie
antwortete „Du spinnst. Es ist scheißkalt. Ich bibbere. Das letzte
Mal, als ich so gefroren habe, bin ich im Rozbrat mit meiner
ehemaligen Band aufgetreten: „Pierdzące Zakonnice“.
Wir spielten Prog-Punk. Kein Wasser, keine Heizung und ein
sibirischer Windhauch kam aus Richtung Minsk. Wer auf Toilette
wollte, hat einen Eispickel in die Hand bekommen, falls das
Plumpsklo wieder zugefroren war. Und am Ende des Abends haben wir
Wahlplakate im Konzertsaal verbrannt, um nicht ganz zu
erfrieren.
Aber wir haben gerockt: Kasia an der Geige, die andere Kasia am
Theremin, ich an der KitchenAid und Anna am Gong und an der
Rezitation. So viel Kunst war nie wieder davor oder danach im
Rozbrat. Leider war es den Pferden zu kalt, so dass die weiße
Kutsche ausgefallen ist. Hier am Hafen ist keine Kunst. Hier ist es
nur scheißkalt. Ich gehe.“
Später, im Chat. Hüpfburgs Schilderung hatte mich an ein Video
erinnert, das ich kurz vorher gesehen hatte: „Wikimedia
Coolest Tool Award 2020.“ in meinen Versuchen, DJ Hüpfburg für
die Wikipedia und ihr Umfeld zu begeistern, postete ich ihr den
Link.
Southgeist: Aber Tools. Nur mit ausgewählten Menschen. Fast
nur Technik und kreative Sachen.
Hüpfburg: Wikipedia spießerfrei? Du meinst, das soll
gehen?
Southgeist: Schau doch mal.
Hüpfburg: Ich sehe jetzt schon drei Minuten lang Berliner
Straßen ohne Ton. Ich dachte schon, meine Lautsprecher wären
kaputt.
Hüpfburg: I like the music.
Southgeist: Eben. Warte erst auf die Tools.
Hüpfburg: 52 Minuten! So lange soll ich Wikipedia schauen?
In der Zeit zerstöre ich zwei Ehen, bringe einen Priester vom
Glauben ab und bringe drei Paare neu zueinander. Sage mir lieber,
was für Tools vorkommen.
Die coolest Tools
Ich erzählte.
Im Video werden vorgestellt: Der AutoWikiBrowser
(Hüpfburg: „Da klingt der Name schon langweilig“), SDZeroBot
generiert Benutzerseitenreports („Mich interessieren weder Benutzer
noch ihre Seiten“), Proofread
Page Extension („Korrekturlesen, geht es noch spießiger?“),
Listen to Wikipedia
(„Schön, aber reichlich Kitsch. Wenn eines Tages zwei Wikipedianer
kommen und einander heiraten wollen, werde ich das Tool in den
Event integrieren“), AbuseFilter
(„Zu sehr Polizei“), LinguaLibre („I
like“), und Pywikibot – ein Tool zum Erstellen weiterer Tools.
(„Das klingt spannend – erzähle mir mehr.“)
Pywikibot
Pywikibot ist ein Framework zum Erstellen von Bots. Oder anders
gesagt: wer sich den Pywikibot installiert, kann mit überschaubarem
Aufwand eigene Bots schaffen. Oder sich an einem der bereits auf
dieser Basis geschaffenen Skripte bedienen. Die Bots können
prinzipiell alles, was menschliche Nutzer von MediaWiki-Wikis auch
können – nur schneller.
Wobei können in diesem Zusammenhang natürlich bedeutet: jemensch
muss dem Bot vorher sagen, was er tun soll. Das dauert länger als
ein Edit. Der Bot kommt sinnvoll ins Spiel, wo es eine hohe Zahl
gleichartiger Edits gibt. Zum Artikelschreiben ist das wenig – zum
Anpassen von Formalien ist es super. Und dazwischen liegt ein
Graubereich. Nicht alles ist sinnvoll, nicht alles ist erlaubt –
und um die Kontrolle zu wahren, hat der Pywikibot einen
automatischen Slow-Down-Mechanismus, der den Bot absichtlich
ausbremst.
Pywikibot geht zurück auf verschiedene Bots und Skripte aus dem
Jahr 2003, existiert in dieser Form seit etwa 2008. Die aktuelle
Variante ist in und für Python 3 geschrieben. Die Community, die
sich um das Framework kümmert, hat eine dreistellige Zahl von
Mitgliedern und ist so international, wie es die frühe Wikipedia
war. Rein aus dem Bauchgefühl heraus würde ich auch sagen, was
Charaktertypen und Soziodemographie angeht, ist die
Pywikibot-Gruppe sehr viel näher an der Ur-Wikipedia als die
heutigen Wikipedistas.
DJ Hüpfburg: „Du sagst es. Alt-Wikipedia. Diese Tool-Awards sind
solche Lebenswerkauszeichungen? Das Bot-Framework gibt es seit fast
20 Jahren, das Proofread-Tool existiert seit fast 15 Jahren. Ist
der Award so langsam oder gibt es so wenig Neues?“
Ich glaube, der Award ist langsam. Beziehungsweise er existiert
erst seit letztem Jahr. Jetzt muss er die ganzen Tools der letzten
Jahrzehnte durchprämieren, damit die nicht vergessen werden. Wie
bei der Wikipedia auch: Die Grundlagen wurden vor langer Zeit
gelegt. Alles, was jetzt kommt, baut darauf an, verbessert, schafft
aber nur selten fundamental Neues.
Change Musiker to Musiker*innen
„Außer dem Tool-Award. Der ist neu? Und dem Video nach zu
urteilen reichlich großartig.“
Yup. Und er hat mir und dir den Pywikibot gelehrt und damit eine
wichtige Aufgabe erfüllt.
DJ Hüpfburg: „Ich kann also auf Basis von Pywikibot alle
‚Musiker‘ in Wikipedia durch ‚Musiker*innen‘ ersetzen?“
Ich: „Theoretisch ja. Praktisch gibt es verschiedene Hindernisse.
Und du wirst auf ewig gesperrt werden.“
DJ Hüpfburg: „Dachte ich. Noch so jung und schon so
strukturkonservativ diese Website. Wäre sie ein Mensch, würde sie
einen beigen Pullunder über weißem Hemd tragen und Leserbriefe an
die Fernsehzeitschrift schreiben. Aber ich kann mein eigenes Wiki
aufsetzen und da noch Herzenslust alles bot-mäßig umbauen?“
Ich: „Yup. Wikidata freut sich auch. Da gibt es noch viel zu tun
und die sind superfreundlich dort.“
DJ Hüpfburg: „Ich auf meinem Pybot einreitend in Wikidata! Das
wäre fast so gut wie im Rozbrat. Mit der Kutsche, die dann doch
nicht kam. Irgendwann im Laufe des Abends spielten wir Mozart. Da
haben die Squatter angefangen mit Äpfeln zu werfen. Wir uns hinter
dem Gong geduckt und ich ein Kitchen-Aid-Solo. Ich erinnere mich
noch an den einen Tänzer, der allein Stand und Luft-Küchenmaschine
gespielt hat. Ein Arm angwickelt am Körper als würde er die
Maschine an sich drücken, mit dem anderen weit ausholende
Bewegungen, um dann auf dem Einschaltknopf zu laden.“
„Leider hatten wir dem Publikum einen Mozart-Schock versetzt und
die wollten uns nicht mehr gehen. Dadurch hatten wir alle
Auftrittsorte in Posen durch. Kasia ging nach Prag und Paris,
Jazz-Theremin studieren. „Ein Juwel unter unserer Studentinnen“
sagte mal eine Professorin. Kasia wäre fast dieses Jahr in der
Philharmonie aufgetreten. Aber Deine komische Wikipedia hat immer
noch keinen Artikel von ihr.“
Ich: „Es ist nicht meine Wikipedia.“
Ruhe. Hüpfburg dachte.
„Dieser Bot. Der kann doch sicher in Wikidata alle Personen
auslesen, die Theremin spielen. Und dann eine Liste in Wikipedia
anlegen. Die regelmäßig erneuert wird. Das müsste doch gehen.
Vielleicht ist es einen Versuch wert.“











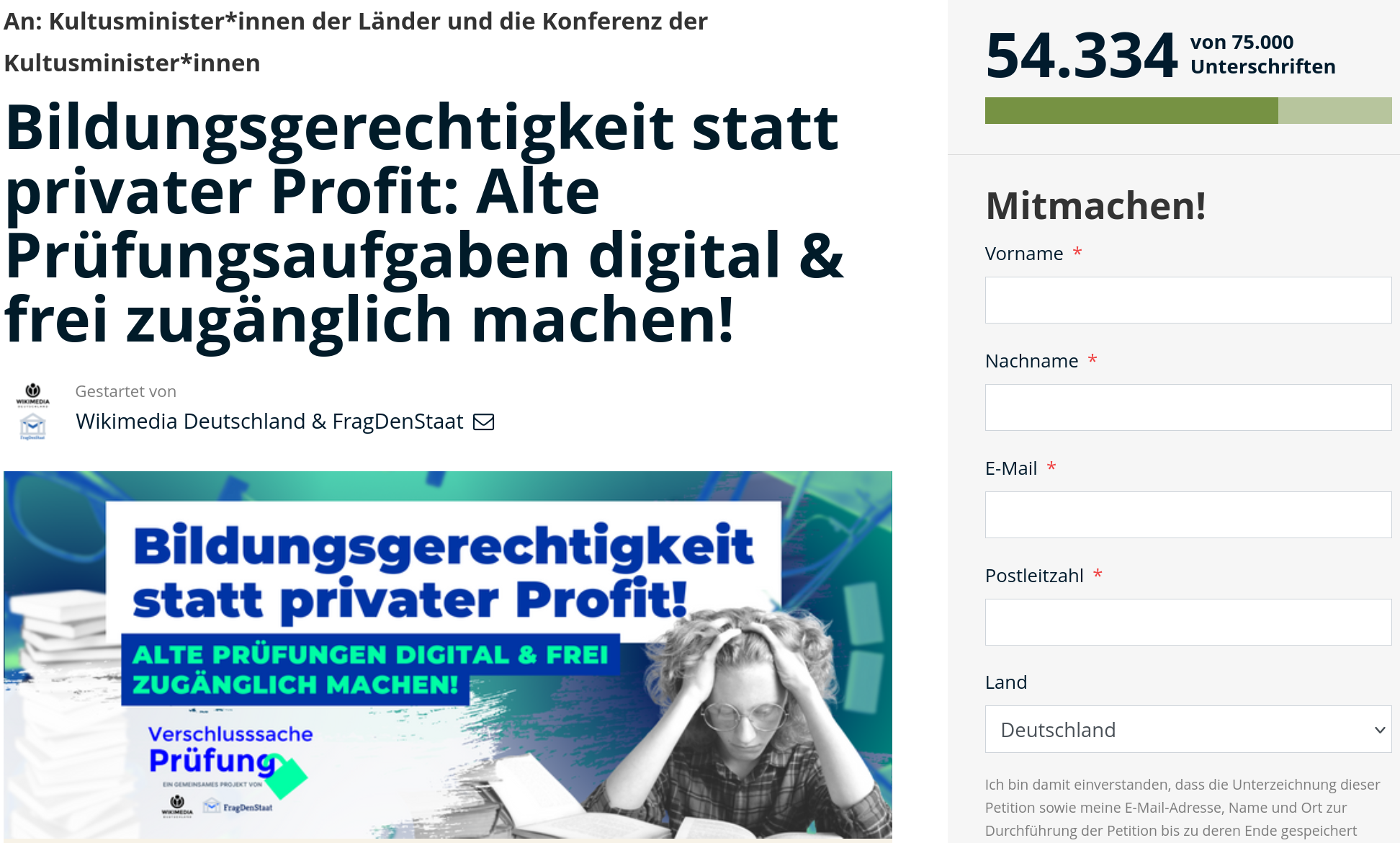














 viele Gespräche mit den Menschen, die uns auf der
viele Gespräche mit den Menschen, die uns auf der




















































_-_n._102_-_Scena_di_genere.jpg)

_-_02.jpg)
.jpg)
_-_n._6204_-_Napoli_-_Fabbrica_di_maccheroni.jpg)
{kind=link}
{kind=link}
{kind=link}
{kind=link}